在软件开发和计算机安全领域,压缩执行文件的现象十分常见。尤其在追求程序体积最小化的场景中,比如演示场景(demoscene)比赛,开发者经常会使用诸如UPX等可执行文件压缩工具,将原本庞大的程序压缩至极限大小,以满足比赛文件大小限制。压缩后的exe文件体积虽小,但其内部包括了一个解压缩代码模块,运行时会先解压真实程序再执行。尽管这样的压缩手法带来了效率与体积的双重优势,但也为逆向分析和调试带来了挑战。本文将从多个角度揭示解包压缩执行文件的技术细节与实践方法,帮助读者理解并掌握这一关键技能。 压缩执行文件的本质是一段压缩代码,该代码自我执行,将原始完整程序解压缩到内存中,然后跳转执行解压缩后的程序。
这种机制使得普通的静态分析工具,譬如IDA Pro或Ghidra,在初期分析时遇到困难,因其无法直接访问程序实际执行的代码逻辑,而只能看到压缩前的加载器代码。因此,如何定位解压代码完成后真实程序的入口点,成为解包操作的关键起点。 目前常见的做法是通过动态调试与模拟运行技术实现对压缩程序的“黑盒”执行。通过构建一个模拟器环境,程序按照正常执行流程运行,当解压循环完成,即将跳转到解压逻辑外的真实程序入口时,及时暂停模拟并截取内存状态。此时内存中保存的是完整解压后的程序代码和数据,利用这些数据即可生成新的可执行文件复原真实程序。此方法不仅适用于UPX,也适合一些老旧版本或非标准压缩器,避免了依赖特定解压工具的局限。
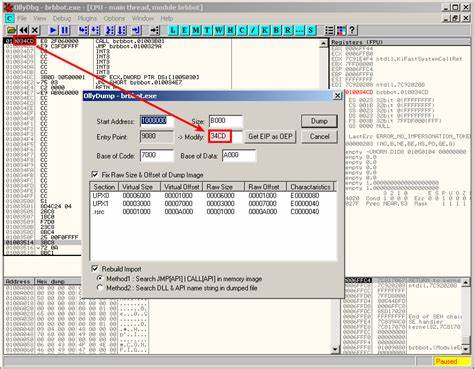
寻找合适的暂停点是解包的首要难题。压缩程序的入口通常包含一段循环结构,负责逐渐写回解压程序代码或数据,最终通过跳转指令切换执行流。解包技术中,分析师往往需要通过静态代码分析找到跳转地址,该地址在程序压缩时并不存在实际代码,是解压后动态生成的内容。常规软件断点由于覆盖目标指令而被解压循环覆盖失效,因此改用断在解压循环最后一条跳转指令,单步跳转后即可准确定位解压程序的入口点。 另一类压缩程序采用将目标地址压栈再通过ret指令跳转的方式,这种结构更易于设置断点并捕获程序流的转折点。通过这些策略,实现在模拟器或调试环境中精确把握程序解包完成的时机,为随后内存镜像提取奠定基础。
生成新可执行文件还面临另一关键挑战:重构导入表(Import Directory Table,IDT)。普通Windows可执行文件依赖导入表来动态调用系统API,如GetStartupInfoA或ShowWindow等。压缩程序为缩减体积,通常仅保留极少导入,并通过解压过程动态加载和解析更多API地址。动态构建的导入表存放于内存中,是解包复原时必须恢复准确的部分,否则静态分析工具无法识别函数调用,逆向分析也无法顺利进行。 由于解压过程通过调用LoadLibrary和GetProcAddress函数获取API地址,但实际写入内存的具体地址并不显式暴露,如何追踪导入函数地址是重中之重。高效的方案是在模拟器中监控和记录所有GetProcAddress调用返回的函数地址,然后扫描程序内存寻找这些地址的存放位置。
一旦定位到内存中的IAT表位置,即可生成符合PE格式规范的导入目录结构,填充导入信息供静态分析工具使用。为避免地址混淆,可尝试多次模拟,采用不同基址或其他参数,使得返回不同地址,交叉比对定位真实IAT位置。 以上方法的优点是完全基于动态执行过程,无需依赖已有解包工具的兼容性,极大增强了解包工作的通用性和灵活性。同时,借助静态分析工具如Ghidra,可以对恢复的程序进行深入反汇编与功能分析,重新理解程序结构,捕获潜藏的代码逻辑及潜在威胁。 值得注意的是,完整的解包工作还需正确调整导出的可执行文件头信息,确保入口点及各段起始地址准确无误。否则导出文件即使代码完整,也可能因入口点错误无法正常加载运行。
通过细致的分析和实验,可以总结出压缩程序常见的文件结构变化规律,辅助自动化解包工具的开发。 综上所述,解包压缩执行文件是逆向工程中的重要技术环节,正确把握执行流程中解压完结点,系统监测运行期间的API函数地址分配,动态生成完整的IAT与IDT,是恢复程序结构的关键。现代工具越来越倾向于结合模拟执行与动态分析手段,不仅提升了解包效率,也为后续精准安全分析和漏洞挖掘提供稳固基础。随着恶意软件和复杂压缩算法的不断发展,解包技术亟需持续创新,帮助业内人士应对日益严峻的安全挑战。掌握这些解包技巧,不仅有助于深入理解程序运行机制,也为编写更安全、稳定的软件提供了宝贵经验。