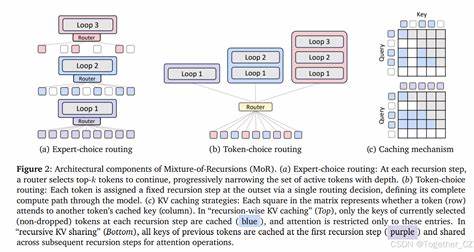
随着人工智能技术的蓬勃发展,尤其是在自然语言处理领域,如何提升大型语言模型的计算效率和预测性能成为了科研和工业界的核心挑战。随着模型规模不断扩大,训练和推理所需的计算资源和存储空间急剧增加,带来了巨大的成本压力和技术瓶颈。在此背景下,Mixture-of-Recursions(简称MoR)作为一种创新性方法,凭借其独特的动态递归深度策略和自适应计算机制,成为解决上述难题的有力工具。MoR不仅实现了参数共享和计算自适应的有机融合,还显著提升了模型的计算效率和推理速度,为未来大规模语言模型的发展开辟了全新路径。首先,理解Mixture-of-Recursions的核心思想至关重要。该技术的基础是递归Transformer架构,它通过在递归步骤中重复使用一套共享的网络层,从而极大地提升了参数利用率。
这种递归结构不仅减少了模型的参数数量,还保证了模型深层次的表达能力,使其在多个任务上的表现不输于更大规模的传统Transformer模型。同时,MoR引入了轻量级的路由器,能够根据不同Token的复杂度动态分配递归深度,实现令牌级别的自适应计算。换言之,不同的输入Token会根据其难度和信息需求,经历不同层次数的递归计算,使得计算资源得以合理分配和集中,避免了无谓的过度计算。这种动态递归深度的机制大幅度提升了计算效率,同时也能保持模型预测的准确性和鲁棒性。另一个值得关注的创新是MoR在注意力机制中的改进。传统的Transformer模型在计算自注意力矩阵时,其复杂度随序列长度的平方增长,成为计算瓶颈。
而在MoR框架下,注意力计算仅限于当前递归深度仍处于活动状态的Token子集,从而显著降低了计算量和内存占用。此外,针对预填充阶段(prefill)带来的延迟和内存压力,MoR提出了KV(键值对)共享的方法,复用第一轮递归的键值对,大幅缩减了预填充时的内存占用和响应时延,进一步增强了部署和实时应用的可行性。从实验角度来看,MoR在不同规模的模型上均展现出亮眼的性能表现。无论是在1.7亿参数量级的中小模型,还是规模达到17亿参数的中大型模型,MoR均能在保持相似训练浮点运算次数的前提下,实现更低的验证困惑度和更优的少样本学习效果。与此同时,其通过集中的递归计算和动态路由带来的推理速度提升,也使得实际部署变得更加高效和经济。MoR所展现的这些优势,使其成为当前模型设计和优化的重要突破口。
传统的模型压缩方法通常在牺牲部分性能的情况下换取计算和内存的节省,而自适应计算方法又往往忽略参数优化的潜力。MoR成功地将两者结合,在参数极致复用的同时,根据输入的不同需求灵活调整计算强度,实现了更好的平衡和优化。这种方法不仅有助于缓解算力瓶颈,还推动了大规模模型向更低成本、更高性能方向发展,具有非常广阔的应用前景。未来,Mixture-of-Recursions将有望在语音识别、机器翻译、文本生成等多个自然语言处理任务中展现更强的适应能力和效率优势。其动态递归机制可进一步结合其他高效模型架构和训练策略,实现更加智能和可扩展的深度学习系统。同时,随着技术的成熟,相关的硬件加速器和计算平台也将围绕这种高效自适应计算核心进行优化,促进人工智能计算生态系统整体升级。
总的来说,Mixture-of-Recursions代表了当前深度学习模型设计在计算效率和表现力上的重要进展。通过巧妙整合递归参数共享与动态深度调控,MoR不仅解决了传统Transformer在大规模应用中的核心瓶颈,而且为未来大型语言模型的创新和实用化提供了强大技术支持。随着研究不断深入和应用不断扩展,Mixture-of-Recursions无疑将在推动人工智能更智能、更高效的发展历程中扮演关键角色,成为普惠科技和工业界的重要助力。