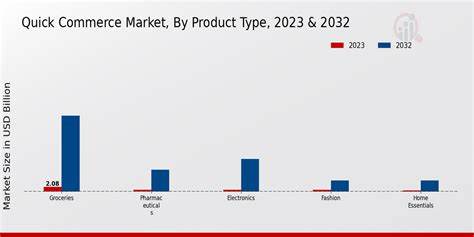
随着快商模式(Quick Commerce)的迅猛崛起,消费者对于即时商品配送和多样化选择的需求不断提升,品牌在这一新生态中的竞争压力前所未有。面对海量、动态的数据环境,品牌获得实时且精准的经营洞察,成为实现销量增长和市场份额提升的核心利器。数据不仅是过去决策的总结,更是推动品牌快速响应市场变化的关键引擎。 当前,快商领域蕴藏着丰富的数据资源:从用户商品浏览、搜索趋势,到城市级别的销售表现以及库存动态,每一笔数据均映射出消费者行为及市场脉络。然而,挑战并非在于数据的获取,而是在于如何将庞杂的数据转化为可操作、即时性的洞察,使品牌能够依托数据驱动的策略快速调整营销和供应链节奏,真正做到了未雨绸缪。 以领先的快商平台Zepto为例,其打造的品牌分析系统通过实时处理千万级别的数据点,帮助各类品牌在多城市、多品类环境中精准把控销售趋势与消费者偏好。
最初,这一系统依靠传统的关系型数据库PostgreSQL完成基本的数据处理,在日复一日的数据同步中积累经验,验证了分析工具构建的基础思路。然而,随着商家入驻增多、产品SKU激增及使用场景复杂化,PostgreSQL逐渐难以支撑海量复杂查询,响应速度和并发处理能力面临瓶颈。 为满足大规模数据的快速分析需求,快商平台引入了专为联机分析处理(OLAP)设计的数据库解决方案。通过对ClickHouse、Apache Pinot和StarRocks等主流OLAP系统的性能测试与功能对比,最终选择了StarRocks,这一决策基于其在查询速度、复杂关联分析能力以及与现有数据生态无缝集成三方面表现出的卓越优势。 StarRocks采用创新的查询优化技术,特别是在多表关联查询方面展现出惊人的效率,能够在数据量超3亿条的表中实现百毫秒级响应,在品牌活动的实时监控和快速决策中发挥了重要作用。此外,StarRocks支持与Kafka消息队列和基于云端的对象存储(例如S3)深度融合,极大简化了实时数据采集与入库的工程复杂度。
快商平台在系统架构上选择了共享无状态(Shared-Nothing)模式,即数据由StarRocks集群本地存储,这一方案以更低的延迟换取较高的性能,极大提升了品牌分析界面的响应速度,支持多品牌、多地域的并发查询。针对数据进入StarRocks的流程,平台实现了多元数据摄取策略:利用Pipe Load持续扫描云端Parquet格式数据,实现批量且高效的数据离线导入;通过Routine Load机制对Kafka流式数据进行实时消费,确保品牌可以在销售和用户反馈发生后的秒级时间内获取分析结果。 整个流数据管道由多环节协同构成。首先是每秒数万条的事件数据通过Kafka集聚,包括用户浏览、商品搜索和订单交付等多维度信息。随后,Apache Flink的流处理作业清洗、转换、聚合数据,以5分钟为窗口间隔进行批量汇总,极大减轻了后端存储和查询的压力。加工后的数据再被推送到Kafka专用主题,由StarRocks Routine Load持续导入数据库,呈现出近乎实时的品牌运营大盘。
由此带来的价值显而易见。品牌合作伙伴不再等待单日或多日的报表更新,而是能即时观察新促销活动的成效,调整库存补货策略,甚至预测用户转化趋势,实现更加灵活且科学的业务运营管理。更重要的是,这种数据驱动的敏捷决策提升了品牌的市场响应速度和用户满意度,增强品牌核心竞争力。 技术方案的不断优化,也为快商生态的未来发展奠定了坚实基础。随着数据规模和复杂度的不断扩大,结合云原生架构的弹性伸缩、高性能计算及机器学习辅助的智能分析,将进一步推动品牌数据洞察的深度和广度。品牌不仅将享有即时的销售与流量报告,还能借助预测分析和个性化推荐,实现精准营销和供应链优化。
总的来看,快商模式的信息化与智能化水平不断提升,“数据驱动品牌成功”不再是口号,而是实实在在的市场能力。通过架构优化和技术革新,快商平台能够提供符合品牌诉求的实时、精准、易用的数据分析工具,引领品牌迈向更加科学、高效的经营模式。未来,在持续的技术创新和数据技术融合下,实时洞察将成为品牌决胜快商市场的核心武器,助力品牌赢得更多消费者青睐并实现持续增长。