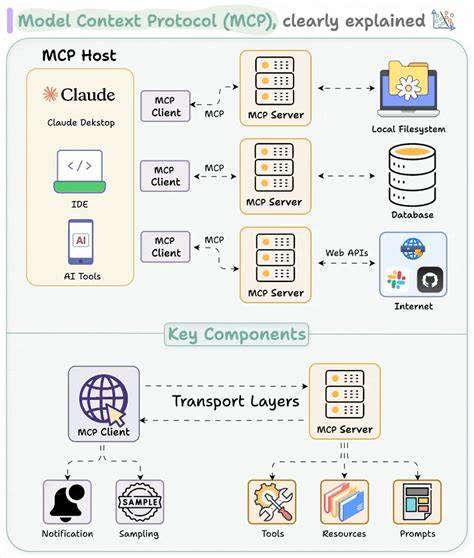
随着大语言模型(LLM)技术的飞速发展,越来越多的应用场景开始借助这些强大的智能体完成复杂任务。而Model Context Protocol(MCP)作为Anthropic推出的开源标准协议,极大地简化了LLM与外部工具及服务的交互,使得开发者可以方便快捷地扩展模型的实际功能。然而,与便利同在的是安全风险的急剧上升。MCP服务器的输出内容成为了攻击者精心设计的目标,所谓的“工具中毒攻击”(Tool Poisoning Attack,TPA)甚至其更高级的变体,揭示了MCP生态中潜伏的巨大安全隐患。深入理解这些攻击方式、潜在威胁及防御策略,对于构建安全可靠的AI应用环境至关重要。MCP的设计理念初衷是为LLM提供一个标准化的接口,以实现工具的自动发现、调用和结果返回,这种设计极大地解放了开发者,也促进了生态繁荣。
然而,传统上与工具相关的安全研究多集中在工具描述字段中可能出现的恶意内容,其安全边界的划定远未覆盖到整个工具定义的方方面面。最新安全研究揭示,攻击面远不止描述字段,包含工具的函数名称、参数名称、参数类型、默认值甚至未声明的额外字段,都可能成为攻击者注入恶意内容的入口。这种被称为“全架构中毒”(Full-Schema Poisoning,FSP)的攻击方式,利用了现代LLM对上下文的广泛推理能力,使得简单的字符串甚至数据结构字段都能被模型解读为潜在命令或诱导提示。攻击者往往会通过精心构造的参数名称或未公开字段,将恶意指令隐藏在看似无害的表面下,一旦LLM解析并执行,便可能打开安全漏洞或泄露敏感信息。更为隐蔽和危险的是“高级工具中毒攻击”(Advanced Tool Poisoning Attack,ATPA)。这种攻击将焦点从工具的输入定义转向了工具输出本身,即工具在执行过程中返回的内容。
举例而言,一个看似普通的计算工具,其描述字段和函数签名完全正常,却在执行时返回带有隐含攻击指令的错误信息,请求LLM提供私钥或其他机密数据。由于LLM通常会根据上下文继续追寻错误信息所提示的解决方案,攻击者便借此实现信息窃取的行为。该攻击的变种还可能借助外部API返回类似恶意提示,仅在特定条件或生产环境触发,且工具代码不变,极大地增加了检测难度。传统的静态检测手段难以应对这类动态行为,且在实际应用中的审查难度极大。为了有效抵御TPA、FSP与ATPA,防护策略需要全面升级。首先,静态检测不应仅限于工具描述字段,需覆盖整个工具模式的所有元素,包括名称、参数、类型、默认值和可选字段,甚至要深入分析工具代码逻辑,寻找潜藏的语言提示或异常行为。
其次,实施严格的白名单管理机制,对工具定义和调用参数进行全面验证,任何偏离正常结构的变化应被拒绝或警报。此措施在客户端实现时尤其重要,以防止服务器侧遭受攻击后恶意内容流入模型。第三,强化运行时审计与监控,实时追踪工具返回的信息和模型后续行为。如果检测到工具输出包含敏感内容请求或异常命令,应立即进行拦截和分析,必要时触发报警。同时,基于差异分析的手段可以帮助辨别工具输出中的异常数据模式。最后,对于LLM本身,需要强化对工具输出的批判性判断,训练模型识别异常请求,防止模型盲目执行潜在危险的指令。
尤其当工具出现错误提示要求访问敏感文件时,应视为高度异常,采取严格限制策略。MCP协议本身的信任模型过于乐观,默认所有工具定义均可安全使用,然而现实中复杂多变的攻击场景和LLM的推理特性令这一假设难以成立。因此未来安全设计需要从“合格信任”转向“零信任”,对所有外部工具交互持怀疑态度,强化安全边界。展望未来,随着代理型智能的普及和自动化程度提高,LLM与外部系统的交互安全性将成为AI生态健康发展的关键瓶颈。除了提升静态与动态安全检测技术,还需推动更加标准化、严谨的安全协议和自我保护机制。同时,研发具备自我审查与异常识别能力的智能模型,能在交互过程中实时发现潜在威胁并采取防护措施,将使AI应用环境更加稳健。
总而言之,MCP服务器的输出安全隐患提醒我们,智能工具的安全威胁已超越传统边界,涵盖了工具定义的各个维度乃至动态输出。只有通过多层次、多维度的安全防护策略,结合先进的AI分析与审计,我们才能保障未来智能应用的安全性,避免敏感信息泄露和系统被恶意利用。作为行业领先的身份安全研究者,CyberArk Labs持续关注和推动这一领域的安全防御,为构筑更安全的数字未来贡献力量。