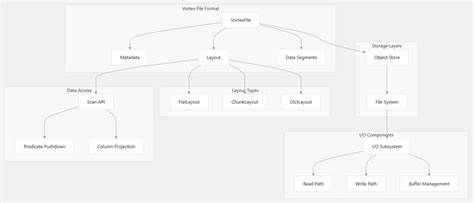
在大数据时代,数据的快速存储、读取和分析成为企业提升竞争力的关键因素。随着数据规模的爆炸性增长,传统的数据存储和处理方式面临着诸多瓶颈,尤其是在文件格式选择上,如何兼顾读取速度、写入效率和压缩性能成为亟需解决的问题。Vortex作为新一代列式文件格式,凭借其卓越的性能表现和良好的兼容性,逐渐受到业界的关注与认可。Vortex是一种高度性能化且可扩展的列式数据格式,设计初衷是优化随机访问速度和扫描效率,显著提升数据的处理速度。相较于广泛使用的Apache Parquet文件格式,Vortex在随机访问速度上实现了100倍的提升,扫描速度提升了10到20倍,写入速度更是快了5倍,同时在数据压缩率方面保持了相当的水准,这使得它在大规模数据处理场景中表现得尤为出色。随机访问能力的提升极大地推动了交互式分析和实时查询的发展。
传统的列式格式虽然在扫描大范围数据时效率较高,但在随机读取单条或少量记录时仍存在较高的延迟。Vortex通过底层优化和智能的数据布局策略,使得这一过程变得极为迅速。这对于需要快速响应的业务场景,如在线仪表盘、日志查询和动态报表尤为重要。相比之下,扫描性能的改进则是推动批量数据处理和离线分析的关键。许多数据仓库和大数据平台依赖大量扫描操作来完成数据聚合和机器学习训练任务。Vortex凭借高效的压缩算法和快速的数据读取机制,能够显著缩短扫描时长,提高资源利用率。
此外,卓越的写入性能使得数据摄取流程更加顺畅。在实时数据流和增量数据处理场景中,文件格式的写入速度直接影响整体数据管道的效率。Vortex的5倍写入速度提高,保证了数据的及时入库和更新,有效支持了实时分析需求。除了性能优势,Vortex还极具扩展性,支持多种数据类型和复杂的数据结构,适应不同的数据模式和存储需求。这种灵活性为企业提供了更多选择空间,可以根据业务特点优化数据格式,从而获得更优的存储效率和查询性能。Vortex目前处于孵化阶段,由知名开放基金会支持,由Spiral团队贡献核心技术。
开源和社区驱动的开发模式为Vortex注入了持续创新的动力,使其不断完善并逐步实现商业级落地。未来,随着更多平台和工具的适配,Vortex有望成为数据处理生态不可或缺的一部分。在兼容性方面,Vortex力求平滑融入现有数据基础设施,支持与主流数据仓库、分析引擎如Apache Spark、Flink等的无缝协作。这样的设计降低了迁移成本和使用门槛,使企业能够轻松体验其带来的性能提升。综上所述,Vortex凭借其显著的性能优势和良好的扩展性,展示了列式文件格式的发展新方向。它不仅满足了当前大数据处理的多样化需求,更为未来数据架构演进提供了坚实基础。
相信随着技术的成熟和生态的完善,Vortex将在数据存储与分析领域发挥越来越重要的作用,推动数据驱动决策和智能应用的更广泛普及。对于希望提升数据处理效率、降低存储成本的企业和开发者而言,及早了解并采用Vortex,将为数字化转型带来显著优势。 。