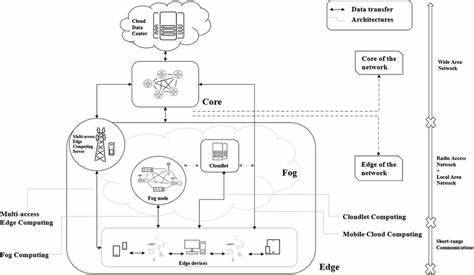
近年来,大规模语言模型(LLMs)在自然语言处理领域展现出卓越的性能,极大推动了智能助手、机器翻译、语音识别等应用的发展。然而,这些模型通常体积庞大,拥有数十亿参数,且需要大量计算资源和存储空间,这给边缘计算环境中的部署带来了巨大挑战。边缘计算强调数据的本地处理与实时响应,能够降低延迟、保障隐私,是推动物联网、智能制造和智慧城市等领域智能化的重要技术基础。因此,实现大规模语言模型在边缘设备上的高效部署,成为当前人工智能和分布式系统交叉领域的热点话题。部署LLMs于边缘计算环境,首先面临硬件资源的极大限制。边缘设备通常具有较低的计算性能、有限的内存和存储容量,而原始模型的体积和算力需求显著超过了这些设备能够承载的范围。
直接将完整模型部署于边缘设备,既不现实,又无法满足实时响应和离线保护隐私的实际需求。为了突破这些限制,研究者提出并实践多种优化技术,其中模型压缩和量化是核心手段。模型压缩旨在通过剪枝、不重要参数删除等方法,减少模型大小和运算量,而量化则将模型权重和激活值转换为低比特宽度数值,进一步降低存储开销和浮点运算成本。这两者相辅相成,显著提升了模型在嵌入式设备上的运行效率,但也可能引入性能损失,因此如何在精度和效率之间取得平衡,成为优化的关键。分布式推理作为另一条技术路径,借助多台边缘设备协同工作,将模型拆分为若干微服务模块分布处理,减轻单台设备压力,同时提高推理速度和系统鲁棒性。通过网络通信协调计算资源分配,确保模型推理的连续性与一致性,促进复杂任务在资源受限环境下的成功执行。
然而,分布式推理引入的通信延迟和网络安全隐患亦需充分重视。近年来,联邦学习被引入边缘计算的LLMs部署中,实现了在多个边缘设备上进行协同训练而无需共享原始数据,有效保护用户隐私。联邦学习通过本地模型更新和全局模型聚合,促进模型持续优化与个性化,尤其适用于数据分散且敏感性高的应用场景。结合联邦学习技术,边缘计算环境能够在维护数据安全的前提下,逐步提升大模型的性能适配能力。本文作者提出了一个整合上述四种技术的统一框架,从算法设计到系统实现,系统性解决了LLMs在边缘设备部署的瓶颈。该框架不仅具备模块化和可扩展性,便于针对不同硬件平台和应用场景优化调节,更通过实验验证,在保证模型准确性的基础上显著提升了响应速度和资源利用率。
该研究表明,单一技术手段难以满足边缘环境的多维度需求,唯有融合压缩、量化、分布式推理和联邦学习,方能实现智能推理的低延迟、高效率和高隐私保障。展望未来,大规模语言模型在边缘计算上的应用必将更加广泛,涵盖智能家居、自动驾驶、医疗诊断、工业自动化等多个领域。随着硬件性能不断提高及算法优化技术持续进步,边缘设备将具备更强的模型承载能力和推理能力。与此同时,对动态环境的适应性、多任务学习能力和节能设计也将成为研究重点。此外,跨设备异构协同计算的模式将逐渐成熟,推动局域网和广域网边缘资源的共享与整合,实现全球范围内的智能边缘网络。边缘计算与大规模语言模型的深度融合,有望极大推动人工智能从中心云到终端设备的普及,使得智能服务更加普适、响应更加迅速,也为数据安全和用户隐私提供坚实保障。
综上所述,优化大规模语言模型在边缘计算环境中的部署,不仅是技术挑战,更是一场融合算力、网络、安全与算法的综合革新。通过模型压缩、量化、分布式推理和联邦学习的协同应用,能够有效破解当前边缘AI的瓶颈,推动智能技术真正走向千家万户,赋能各行各业的数字化转型与创新发展。随着研究不断深入和落地项目增多,未来边缘智能的生态系统将愈加完善,成为新时代人工智能发展的关键支撑。