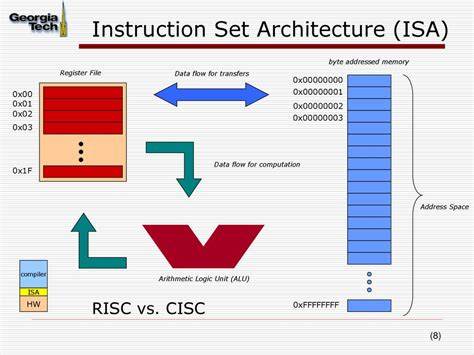
随着计算需求呈指数级增长,现代处理器设计面临着前所未有的挑战。尤其是高性能CPU和GPU,如何高效管理寄存器资源,成为限制其指令并行执行和性能提升的关键瓶颈之一。近年来,基于距离的指令集架构(Distance-Based ISA)应运而生,作为一种创新的寄存器管理方法,为提升处理器执行效率带来了革命性变革。传统的指令集架构多采用基于寄存器编号的操作数指定方式,这种方式依赖复杂的寄存器重命名机制,既增加了硬件设计的复杂性,又带来了功耗和芯片面积的显著负担。尤其在当前高宽度、超大规模指令级并行(ILP)执行的时代背景下,这种传统机制的弊端更加突出。基于距离的指令集架构试图从根本上解决寄存器重命名带来的瓶颈。
其核心思想是通过“距离”来指定操作数,而不是使用固定的寄存器编号。换句话说,指令中引用的操作数以相对于当前指令之前产生的指令数量为单位来表示,这种设计类似于编译器中的静态单赋值(SSA)形式,确保每个值只被定义一次且不会被覆盖。此方法消除了伪数据相关性,从而极大减少了寄存器重命名的需求和相关硬件资源的消耗。基于距离的设计不仅能够简化调度器,实现更紧凑的硬件布局,还能提高指令流水线的执行效率。例如,STRAIGHT架构直接以距离来表示操作数,省去了寄存器重命名逻辑,降低了芯片的复杂度和功耗。Clockhands架构则通过引入多组寄存器并结合距离标识,改善了对短生命周期和长生命周期值的管理,提升了灵活性。
专为GPU设计的TURBULENCE架构,通过混合采用距离和传统寄存器编号方式,兼顾了性能与兼容性,特别适合并行计算密集的图形处理任务。这些架构设计上的创新,为未来能够支持每周期执行二十条及以上指令的高宽度CPU提供了强有力的技术支撑。基于距离的指令集还能缓解由分支错误预测带来的寄存器重命名回滚复杂性。传统架构中,分支误判需要恢复寄存器映射表状态,且该过程随乱序执行指令数的增加而变得更加复杂和耗时。而距离化操作数方式天然避免了寄存器的覆盖问题,从根源上降低误判恢复的难度和成本。然而,将基于距离的设计推向实际应用,也面临不少挑战。
首先是编译器的支持问题。由于操作数距离依赖于程序的执行路径,分支和循环结构使得距离计算复杂。为保证程序正确执行,编译器需引入NOP指令或复制指令调整距离一致性。当前基于LLVM的STRAIGHT编译器已经成功通过了SPEC CPU2017基准测试,证明了基于距离的编程模型可以实现良好的兼容性和易用性。其次,硬件实现的复杂性也不容忽视。虽然移除寄存器重命名硬件,从理论上大幅减少了硬件面积和功耗,但要保证处理器整体架构的稳定性和高效性,需要对流水线、调度器和寄存器文件设计进行全面调整。
幸运的是,研究团队已经采用SystemVerilog设计并验证了STRIAGHT和Clockhands架构的处理器原型,并成功制造出了多代芯片。这些芯片在实际FPGA或硅片测试中运行CoreMark等标准测试并取得了预期的性能验证,表明基于距离架构已经从概念验证迈向实用阶段。值得注意的是,GPU领域对于基于距离的指令集架构尤其具有天然优势。相比CPU,GPU应用普遍通过中间表示(IR)分发程序代码,厂商能够灵活调整内部指令集以适配新架构。TURBULENCE架构正是基于这一特点设计,通过混合使用距离和寄存器编号,兼顾了执行效率和指令集兼容性,未来有望实现GPU性能的显著提升。当前半导体工艺的进步趋缓,传统靠工艺提升带来性能增长的时代逐渐结束,架构创新成为推动硬件性能提升的关键驱动力。
基于距离的指令集架构为处理器提供了全新的设计思路和技术手段,对于实现更高效的指令调度和寄存器管理、提升指令并行度具有重要意义。展望未来,基于距离的架构将在高性能CPU和GPU设计中扮演重要角色,为解决当今处理器性能瓶颈带来曙光。设计者、开发者以及研究者应深入探索其在多核、多线程、异构计算环境中的应用潜力,推动相关编译技术和硬件实现的成熟,携手迎接下一代计算架构的挑战。总而言之,基于距离的指令集架构突破了传统寄存器管理的局限,简化了硬件复杂度,提高了性能扩展性。其在处理器领域的应用前景广阔,或将成为未来数年内计算体系结构变革的重要引擎。借助这项技术,行业有望打造出更加高效、能耗更低且更具扩展性的计算平台,为人工智能、大数据处理、高性能计算等前沿领域提供坚实的硬件基础,推动整个信息技术生态迈入新纪元。
。