随着现代应用的复杂性不断提升,数据库性能优化变得尤为关键。在众多数据库技术中,PostgreSQL以其强大的功能和灵活的索引方案被广泛应用。而在实际场景中,“值在范围内”类型的查询需求十分普遍,比如实验版本管理、功能灰度发布等。如何利用正确的索引策略,提升范围查询的效率,成为数据库开发者关注的重点。 首先理解查询的典型场景非常重要。假设在某个应用场景中,需要根据平台和客户端版本号,查询该版本号所处范围内的实验配置。
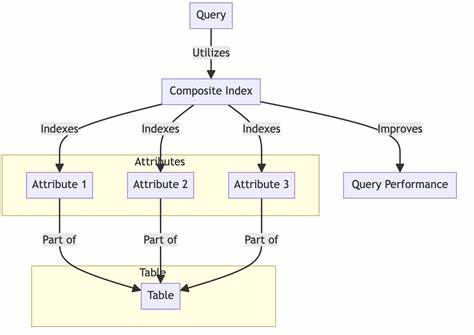
换言之,就是判断一个具体的build_number是否落在某个范围区间内,同时满足平台条件。这个场景的SQL查询通常会写成:“SELECT * FROM experiments_build_tracking WHERE platform = :platform AND :build_number BETWEEN build_min AND build_max”。看似简单的查询,随着数据量级的上升,如果没有合适的索引支持,会导致全表扫描,查询响应时间飙升。 首先尝试的优化方案往往是使用PostgreSQL的复合B-tree索引,将平台(platform)和区间跨度的边界(build_min, build_max)作为索引字段。虽然这种简单的复合索引能够提升部分查询效率,但针对“值落在某一范围”的条件,传统B-tree索引无法充分发挥优势。因为B-tree索引是有序结构,通常用于单值匹配或范围扫描,而对于“值在区间内”的判断,本质是一种范围包含关系查询,普通B-tree索引不能直接支持快速检索所有包含指定点的区间。
为满足此需求,PostgreSQL提供了多种特殊索引类型,其中GiST(Generalized Search Tree)索引尤为适合处理区间和范围数据。GiST是一个框架,支持多种自定义索引策略,其中内置的范围类型支持以及相关操作符能大大优化此类查询。PostgreSQL原生支持范围数据类型,如int4range, int8range和numrange,可以用于存储区间边界。通过将build_min和build_max字段合并为一个int4range类型的字段,再结合GiST索引,可以实现高效的“点包含于区间”的查找。 数据模型上的调整是优化的关键步骤。相比传统的两列区间表示,单一的范围类型不仅代码简洁清晰,还能让索引机制精准匹配查询需求。
创建GiST索引后,查询语句可用范围操作符“@>”替代BETWEEN条件,即“SELECT * FROM experiments_build_tracking WHERE platform = :platform AND range_column @> :build_number”,利用GiST索引快速定位包含指定值的区间。 除了使用GiST索引,PostgreSQL中还有SP-GiST索引,特化处理空间分割的数据结构,适合高维和稀疏数据的查询,但对于简单范围查找,GiST已足够稳健和高效。实际生产环境中,选择最合适的索引方案,需要结合数据分布、查询模式和维护成本综合评估。 除了索引类型本身,合理选择数据类型也极其重要。比如选择整数范围而非字符串类型的版本号,可以显著减少存储空间和索引负载,提高查找速度。如果版本号复杂,还可采用版本号转整数的方法,通过公式编码不同版本号段,保证范围连续且可排序,从而适配范围类型和索引。
性能优化还需注意索引的维护和更新频率。在频繁更新的场景中,GiST索引虽然强大,但索引更新的开销不容忽视,必须权衡查询性能和写入延迟。此外,配置合理的统计信息采集和分析,能帮助查询规划器更准确地选择执行计划,进一步提升性能。 开发者在实战中不能忽视查询边界条件的细节。比如,区间是闭区间还是开区间,边界值是否包含,在SQL语句和范围数据定义中要精确匹配,避免出现遗漏数据或重复匹配的情况。PostgreSQL范围类型支持多种边界模式,利用起来非常灵活。
在实际应用中,案件规模从几千到几百万条实验记录不等,使用GiST范围索引的查询响应时间能够轻松缩减到毫秒级,极大提升用户体验和系统吞吐能力。更重要的是,优化空间不仅限于单表查询,通过合理的联合索引和分区策略,还能支持复杂的多维度查询场景,如按产品线、用户标签或地理区域进行筛选。 总而言之,PostgreSQL在优化范围查询方面提供了丰富且强大的工具。通过将传统的复合索引迁移到基于范围类型的GiST索引,开发者可以显著提升数据库性能,实现精准且高效的范围检测查询。掌握这些技术不仅能够应对当前的大数据挑战,也为未来多样化的数据场景奠定基础。随着应用对实时性和响应速度要求的提升,深入理解并合理应用PostgreSQL的索引机制,成为数据库设计中的重要竞争力。
希望每位开发者都能利用好PostgreSQL强大的功能,把复杂查询变得简单而高效,推动产品功能持续迭代和用户体验升级。