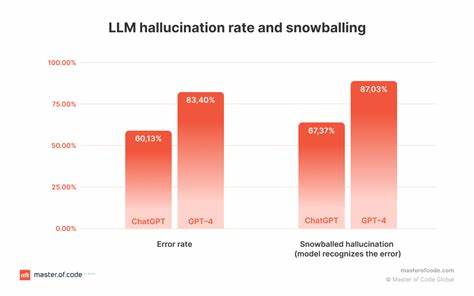
近年来,大语言模型(Large Language Models,简称LLM)如OpenAI的GPT系列迅速发展,广泛应用于文本生成、智能问答、内容创作等多个领域。这些模型以其强大的语言理解和生成能力,极大地推动了人工智能技术的边界。然而,随着应用的深入,一个普遍存在的问题逐渐显现 - - 模型生成内容中的幻觉现象(Hallucination)。所谓幻觉,指的是模型在生成文本时,产生了不符合事实、虚假的信息,甚至是逻辑错误的内容。这不仅影响用户体验,也对实际应用带来了潜在风险。针对这一挑战,CompareGPT作为一款创新工具应运而生。
它通过比较多个大语言模型的输出,来检测和识别可能的幻觉,帮助用户更准确地理解和使用模型生成的文本。 幻觉现象之所以成为困扰研究者和开发者的难题,部分原因源于大语言模型的训练方式和推理模式。LLM主要通过大规模语料库学习语言的统计特征和上下文关联,但它们并不具备真正的事实验证能力,因此在面对未知或复杂问题时,容易生成看似合理但实际上错误的信息。这种"自信而不真实"的表现,有时会误导用户做出错误判断,尤其在医疗、法律、金融等敏感领域,准确性显得尤为重要。 CompareGPT的核心理念是通过多模型对比的方法,利用不同模型在知识储备、训练数据和算法架构上的差异来发现幻觉。当多个独立模型针对相同输入生成回答时,大多数模型产生一致或高度相似的答案,通常意味着内容的准确性较高。
而若出现明显分歧或个别模型提供了与众不同的信息,则可能暗示存在幻觉。通过这种交叉验证机制,CompareGPT可以有效区分真实与虚假的输出,辅助用户筛选和确认信息的真实性。 技术层面上,CompareGPT整合了来自OpenAI、Google、Anthropic等多个顶尖机构的语言模型,并设计了一套统一的对比分析框架。输入信息被同时发送到各个模型,生成文本后通过语义匹配、逻辑推理以及事实核验等手段进行综合评估。系统不仅关注文本表面的相似度,还深入分析内容上下文、细节差异和潜在偏差,从而形成全面的判断依据。此外,CompareGPT提供了友好的可视化界面,使用户能够直观了解不同模型的回答差异与共识,增强用户的决策信心。
在实际应用场景中,CompareGPT展现出多方面的价值。对于内容创作者,利用该工具可以避免因模型幻觉导致的错误信息传播,提升作品的专业性和可信度。教育领域的师生可以借助CompareGPT获得更准确的学习辅导,避免误导性知识。企业在客户服务、自动化报告生成等环节应用该技术,亦可显著降低因信息错误引发的风险。其开放的接口和高度可扩展的架构,也为开发者提供了灵活集成的可能,推动更多创新应用的诞生。 未来,随着多模态人工智能和知识增强技术的发展,CompareGPT有望进一步升级,结合图像、视频等多类型数据进行综合比对,实现更为精准和智能的幻觉识别。
同时,结合知识图谱和实时数据源,提升模型的事实校验能力,减少幻觉产生的根源。从长远来看,这种多模型对比和事实验证的方法,有助于构建更加安全、可信赖的人工智能生态环境,推动AI技术走向更广泛和深入的社会应用。 总结来看,CompareGPT通过创新的多模型对比策略,为解决大语言模型幻觉现象提供了强有力的技术支持。它不仅提升了生成文本的可信度,也为用户提供了更加透明和可靠的人工智能使用体验。随着人工智能技术的不断进步和应用场景的多样化,类似CompareGPT这样的工具必将成为保障AI输出准确性的重要利器,引领行业迈向更加智能和负责任的未来。 。









