近年来,大语言模型(LLM)在自然语言处理领域的应用取得了突破性进展。随着技术的发展,如何让这些模型更有效地适应特定下游任务,成为研究者关注的焦点。传统上,强化学习(Reinforcement Learning, RL)被广泛用于调整和优化模型策略,尤其是采用策略梯度和回报反馈的方法,如Group Relative Policy Optimization(GRPO)。不过,此类方法通常依赖大量的训练轮次和稀疏的标量奖励信号,对于计算资源和时间成本提出了高要求。针对这一现实瓶颈,GEPA(Genetic-Pareto)应运而生,作为一种全新的提示优化器,GEPA通过引入自然语言反思机制,实现了对大语言模型提示的高效演化和升级,在实际应用中展现出超越强化学习的潜能。GEPA的核心理念是利用语言自身的可解释性,使模型能够通过“试错”和“反思”来识别现有提示的不足,进而生成更优的提示版本。
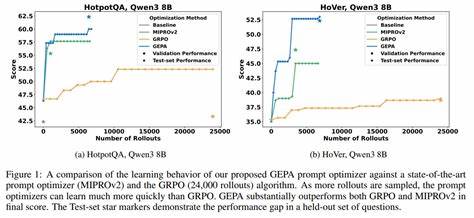
具体而言,GEPA会采集系统整体运行轨迹,包括推理过程、调用工具以及工具输出等信息,然后通过自然语言描述对出现的问题进行诊断。这种基于语言的反思模拟了人类专家通过自我审视不断改进方案的过程,极大地丰富了模型从外部反馈中学习的维度。不同于RL依赖的单一稀疏奖励信号,GEPA同时借助多样化的反馈信号构建帕累托前沿(Pareto Frontier),代表一系列在不同指标上表现优异的提示组合。通过对这些多目标优化结果的综合分析,GEPA能够提炼出更具适应性和泛化能力的提示演化策略。实践证明,GEPA在多个任务中均取得了显著优势。相比GRPO,它在平均表现上提升了约10%,最高可达20%,同时训练过程所需的rollout数量减少了近35倍。
这不仅意味着优化速度大幅提升,还反映出GEPA在数据效率和计算效率方面的显著提升。此外,GEPA还超过了目前领先的提示优化器MIPROv2,在两个主流大语言模型上的表现提升均超过10%。从实用角度来看,GEPA不仅适用于训练阶段,还展现出作为推理时搜索策略的潜力,特别是在代码优化领域中取得了富有前景的成果。GEPA的设计充分体现了人工智能系统自我反思和自我调整的能力,在自然语言理解和生成的语境下加速模型智能的进化。这一突破为提示工程领域带来了新的思路,即通过语言的解释力和多目标优化的融合,获得更高效、可解释且通用的提示优化方案。未来,随着GEPA方法的不断完善和扩展,其应用范围有望覆盖更多复杂任务和跨领域场景,从而推动大语言模型在实际生产力工具中的广泛普及。
同时,由于GEPA显著降低了所需的训练资源和时间成本,其在工业界的落地和商业化前景同样引人期待。总之,GEPA通过反思式提示演化,提供了一条比传统强化学习效率更高、效果更佳的新路径,彰显了语言作为学习媒介的巨大潜力。在人工智能技术日益成熟的今天,如何充分发挥自然语言的内在优势,将成为推动智能系统创新和发展的核心动力。