近年来,随着人工智能技术的高速发展,大型语言模型(LLM)如BERT在自然语言处理领域取得了突破性的进展。与此同时,RISC-V作为开放指令集架构,以其灵活的模块设计和可扩展性,正逐渐成为AI硬件加速和嵌入式系统的理想选择。将大型语言模型成功编译并优化运行于RISC-V平台,不仅能够让AI计算更贴近硬件,从而提升性能和能效,还为推动开源硬件生态发展注入新的活力。本文将结合最新技术动态,详细介绍如何通过现代编译手段,将大型语言模型顺利转换为适合RISC-V执行的可执行代码。首先需要理解RISC-V体系结构的优势及其矢量扩展的特点。RISC-V基于简化指令集计算(RISC)原则,拥有模块化设计,允许用户根据需求增添或去除指令集,提供了高度灵活的硬件设计空间。
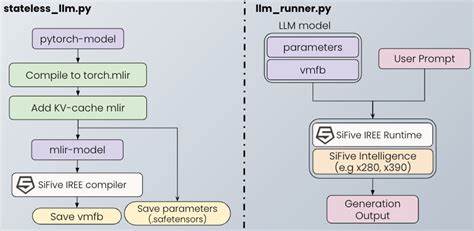
特别是其向量扩展(Vector Extension,RVV)支持通过引入多个向量寄存器和矢量指令,实现对多数据元素的并行处理,大幅提升了AI与机器学习算法的计算效率。向量寄存器长度可调节的特性,也给软件开发带来了极大的适配空间,方便针对不同硬件进行性能调优。在软件层面,Google开源的IREE(Intermediate Representation Execution Environment,通用中间表示执行环境)成为执行深度学习模型不可或缺的工具。IREE基于MLIR(Multi-Level Intermediate Representation)生态系统,支持将Python环境下的深度学习框架模型高效转化为底层硬件可执行代码。具体到大型语言模型的编译,首先通过torch_mlir库将BERT等模型导出成STABLEHLO(MHLO)中间表现形式,这是一种专门针对机器学习操作设计的高抽象级别表示,具有跨平台移植和性能优化的优势。转换过程需要解决多返回值处理等编译复杂性问题,通常会以包装类形式封装模型的前向推理方法,确保编译流水线的完整顺利。
完成中间表示之后,结合LLVM编译基础设施的强大后端能力,通过指定目标三元组(Target Triple)和CPU特性,准确描述RISC-V的64位架构及其扩展指令集支持,使生成的代码专业匹配目标硬件。LLVM项目一直是开源编译器技术的核心引擎,能够灵活支持包括RISC-V在内的多种架构,持续更新的版本为AI模型的加速和优化提供了稳定保障。调用iree-compile命令行工具时,需传递丰富的参数,如后端类型(llvm-cpu)、ABI规范(lp64d)、向量扩展特征(+v)、浮点支持(+f,+d)以及自定义向量长度配置等。这些标志确保编译器生成的二进制文件不仅拥有正确的指令集,还能最大化利用矢量扩展,进而提升推理时的吞吐量和功耗效率。最终的输出为一个vmfb格式的IREE二进制文件,内部封装了RISC-V指令的ELF可执行文件。通过LLVM工具链中的llvm-objdump等反汇编命令,开发者可以直接分析生成的汇编代码,确认是否有效利用了矢量指令vse32.v等高性能操作指令,与此同时帮助调试和进一步性能调优。
这使得用户能深入理解模型经过的每一个编译阶段,确保计算逻辑的完整传递和硬件执行的精准契合。值得关注的是,RISC-V的开放特性允许硬件定制者根据应用需求调整矢量长度及寄存器宽度,软件层面的灵活编译配置正好呼应这一智能适配,推动应用端和芯片设计端形成良性互动,全面提升AI推理系统的定制化水平。基于上述技术框架,整个流程不仅保障了从高层深度学习模型到硬件指令流的平滑转换,也为未来支持更多复杂模型和混合运算架构奠定了基础。随着OpenXLA、IREE等项目的成熟,越来越多开源模型能够通过类似路径高效落地到RISC-V,这为推动国产硬件生态自主创新以及AI领域的软硬结合带来深远影响。整体来看,将大型语言模型编译到RISC-V是一项跨领域的技术挑战,融合了前沿的编译技术、硬件架构知识和机器学习理论。解决这一问题需要科研人员、工程师和开源社区的持续协作。
未来随着支持工具链、硬件设计的不断升级和标准完善,基于RISC-V的AI计算能力将更加突出,推动智能设备在边缘计算、嵌入式系统、云端推理等多场景爆发出更强大的应用潜力。综上所述,从理解RISC-V架构和Vector扩展特性开始,借助MLIR和LLVM的编译生态,再到利用IREE完成中间表示的转化并生成符合RISC-V目标的二进制文件,完整流程展现了现代编译技术如何赋能AI模型在前沿硬件上的高效运行。持续关注相关工具链的更新并结合具体硬件应用场景设计合理编译策略,才能最大化发挥大型语言模型的性能优势,助力智能计算迈向新高度。