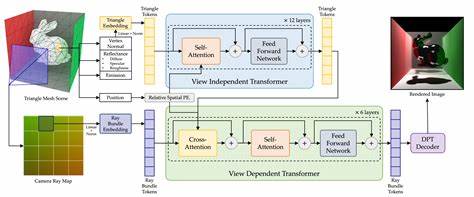
3D渲染作为将三维模型转换为二维图像的核心技术,广泛应用于游戏、电影、虚拟现实以及建筑可视化等领域,长期以来依赖于基于物理的传统方法,如光线追踪和光栅化。这些方法通过精确的光照模拟和数学公式,实现了真实感渲染,但也面临着计算复杂度高、效率有限以及对复杂场景和材料支持不足的挑战。近年来,深度学习和神经网络的兴起为3D渲染带来了全新的可能性,开启了神经渲染这一新兴研究方向。神经渲染结合了深度学习与传统图形技术,摒弃了对物理光学规则的显式建模,能够通过端到端训练自动学习光传输规律,灵活适应各种场景和任务,但现有大多数方法仍受限于只处理二维图像输入,无法直接处理三维几何与材质数据,并且每个场景通常需单独训练,限制了其通用性。为突破这些瓶颈,微软研究团队提出了RenderFormer,这是首个基于纯神经网络实现完整3D渲染流水线的架构,无需依赖传统光线追踪或光栅化技术,能够对任意三维场景支持全局光照效果。RenderFormer采用三角形令牌作为场景基本单位,每个令牌包含空间位置、表面法线、漫反射及高光材质属性等信息,连同灯光发射值,全面描述了场景结构和光照环境。
通过引入射线束令牌,模型将每个输出像素对应的观察方向编码进网络。为提升计算效率, RenderFormer将像素划分为矩形区块,批量处理射线,兼顾精度与性能。架构设计方面,RenderFormer构建了双分支Transformer网络,区别处理视角无关和视角相关的特征。视角无关分支通过三角形令牌间的自注意力捕获阴影和漫反射光传输等信息,真实还原场景中不随观察方向变化的光照部分。视角相关分支则通过三角形与射线束的交叉注意力模拟可见性、反射和高光等反射特效,精细呈现视角依赖的视觉效果。额外的图像空间效果,如抗锯齿和屏幕空间反射,则通过射线束令牌的自注意力机制完成,保证画面质量和细节。
为验证模型设计的有效性,微软团队进行了详尽的消融实验和可视化分析,证明各模块在渲染流程中的关键作用。通过训练一个仅含视角无关分支的解码器,RenderFormer成功生成了准确表现阴影和间接光照的漫反射渲染结果。视角相关分支的注意力权重可视化则展示了模型能够捕获复杂的反射关系,如茶壶表面像素关注其自身三角形及邻近墙面的反射影响,彰显材质变更对高光锐度和强度的调控能力。训练数据方面,RenderFormer利用了庞大的Objaverse数据集,涵盖超过80万个带注释的三维物体。研究人员设计了四种场景模板,每个场景随机组合1到3个物体所在材质,采用Blender Cycles渲染引擎在高动态范围内模拟多样光照与相机角度,从而获得丰富而多样的训练实例。模型由两阶段训练组成,初期在256×256分辨率下训练50万步,处理最多1536个三角形,随后提升至512×512分辨率训练10万步,支持更复杂的4096个三角形场景输入。
拥有2亿多个参数的RenderFormer能够很好地泛化至复杂真实世界场景,真实捕捉阴影、漫反射及反光高光细节。除静态图像渲染外,RenderFormer还能逐帧生成连续视频,支持视角变换与场景动态变化的建模,展现了神经渲染在动画及实时渲染领域的潜力。这项突破性工作不仅向传统光线追踪和光栅化发起挑战,更为未来结合AI与图形技术指明了方向。尽管RenderFormer在神经渲染领域取得了重要进展,但仍面临如何处理更庞大复杂的几何体、复杂材质以及多样光照环境的挑战,未来需要进一步优化模型结构、加强场景表达能力以及提升计算效率。基于Transformer的架构特点赋予了RenderFormer良好的扩展潜力和集成能力,为视频生成、图像合成、机器人感知和具身智能等跨领域应用奠定了基础。微软研究团队期待RenderFormer成为推动视觉计算和智能环境变革的重要基石,引领神经渲染技术迈入新的发展阶段。
随着人工智能技术的不断成熟,利用深度神经网络推动3D渲染方法的革新,将极大促进虚拟现实、游戏设计和影视制作等多个产业的进步。RenderFormer作为先进的实例,展示了AI技术如何深入图形渲染底层,突破传统限制,实现更加灵活、高效和逼真的视觉表现。未来,随着模型能力提升与硬件加速的普及,基于神经网络的3D渲染有望成为主流技术之一,推动数字内容创作进入智能化新时代,助力开发者和艺术家释放更丰富的创作潜力。 。