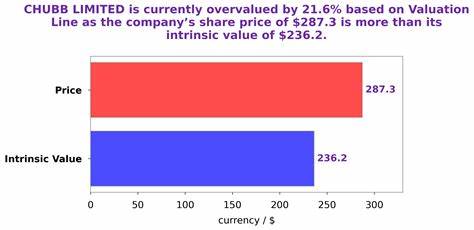
随着人工智能技术的飞速发展,长篇文本生成在新闻报道、学术写作、内容创作等多个领域展现出广泛应用价值。然而,如何确保机器生成的文本内容真实可靠,特别是其中包含的事实性声明的准确性,成为学术界和工业界亟待解决的难题。事实性评估不仅影响用户对生成文本的信任度,也决定了应用场景的实际落地效果。当前,传统的事实性评估体系多依赖于将文本拆分为“原子声明”,并通过知识库如维基百科进行验证。这一类方法如FACTSCORE和SAFE虽然推动了事实验证技术进步,但存在对不同类型文本场景适用性的限制。它们往往默认所有声明都具有可验证性,然而,现实长篇文本中往往同时包含可验证和不可验证的信息,这给评估体系带来挑战。
针对上述不足,VeriScore提出了一种创新的多任务事实性评估框架。它不仅能够自动提取文本中的原子声明,还能区分声明的可验证性,从而实现对多样化长篇文本生成内容的适配。VeriScore既支持封闭权重模型,也能在开源模型基础上进行微调,极大增强了其灵活性与普适性。通过人类评估,VeriScore抽取的声明在合理性和逻辑性方面优于传统方法,显示出更强的事实语义理解能力。多任务、多模型的测试结果进一步印证了VeriScore的准确性与稳定性,尤其是在生物传记生成与长篇问答等高事实密度任务上的突出表现,揭示了不同任务间事实性评估的差异性和复杂度。 从技术角度分析,VeriScore核心创新在于其声明提取和验证两步法的高度协同。
首先,通过自然语言处理技术内嵌的上下文理解能力,精准切分文本中的原子事实单位。其次,借助强大的预训练语言模型与知识库接口,动态验证声明的真伪,尤其对开放领域的事实能够进行高效核实。此外,VeriScore引入了声明的可验证性分类机制,使评估结果更加合理地聚焦于可证伪信息,避免因不可验证内容引发的误判和评价偏差。这种设计使得事实性评估不再局限于传统封闭领域验证,而迈向更广泛的实际应用。 深度学习模型如GPT-4o凭借其大规模训练和强大语言理解能力,在长篇文本生成中表现卓越,VeriScore的评估结果证实它在事实性维护方面处于领先地位。然而,开源社区的模型如Mixtral-8×22正在不断缩小差距,体现了开放研究环境促进技术均衡发展的趋势。
不同模型在不同任务上的事实性表现差异也为模型设计和优化提供了有益参考。例如,模型在适应复杂生物传记内容的事实核查能力,往往优于在开放问答场景下的事实生成准确性,这提示未来需要针对具体任务定制化评估策略。 从应用角度看,事实性评估不仅是学术研究的热点,更成为内容生成平台、智能问答系统、新闻聚合服务等商业应用的关键组成部分。高质量的事实验证手段能够有效防止虚假信息传播,提升用户体验和平台公信力。尤其在当前假新闻泛滥、大规模语言模型生成内容泛滥的背景下,如何借助先进评估指标如VeriScore保障输出结果的真实性,成为业界急迫需求。未来,结合跨模态数据源、多语种知识库以及实时动态信息的事实性评估体系将逐步完善,为人工智能内容生成提供更坚实的可信底座。
面对快速变化的自然语言生成场景,持续深化事实性评估方法的研究是推动行业持续健康发展的关键。研究者和工程师需要关注评估指标的泛化能力,增强对不可验证和模糊事实处理的智能判别,同时优化指标的计算效率,满足大规模文本生成的实时反馈需求。政策制定者和内容审核组织亦应重视科学的事实性评估标准建设,推动产业规范化发展。全民信息素养提升、系统化事实验证工具普及,将共同构筑可信的数字信息生态环境。 综上所述,长篇文本生成中的事实性问题日益凸显,传统验证指标的局限性催生了VeriScore等创新评估工具。VeriScore通过智能化声明提取与验证机制,实现对多任务、多模型长文本事实性的精确评估,为自然语言生成领域注入新活力。
随着技术持续进步和应用不断深化,事实性评估体系将成为保障数字内容质量和真实性的核心基石,引领人工智能写作迈向更加可信和可靠的未来。