近年来,随着人工智能技术的飞速发展,评估模型能力的各种基准测试层出不穷。在众多测试中,《人类最后的考试》(Humanity's Last Exam,简称HLE)因其高度挑战性和结合多学科知识而备受关注。作为一项集数学、物理、化学、生物、工程等多个领域于一体的综合考试,HLE意图突破传统评测的桎梏,设置难度更高、涵盖领域更广的题目,以客观反映AI模型在前沿科研层面的能力。然而,最新研究指出,尤其是在化学和生物学领域,HLE中大约29%的题目答案存在较大争议,科学文献与答题标准存在直接冲突,这一现象值得深刻探讨。HLE为何会出现如此高比例的“错误”答案?其设计理念、评审机制又存在哪些不足?这些问题不仅反映了AI评测的复杂性,也揭示了当前科学知识前沿的动态与不确定性。HLE的设计者试图追求难度极高的题库,刻意纳入了许多现阶段前沿模型难以正确作答乃至衡量自身极限的题目。
与以往如MMLU此类能够让模型达到90%以上准确率的标准化考试不同,HLE的特殊之处在于题目选取刻意避免简单直观,力求“卡住”最先进的语言模型。此策略从挑战极限的角度来说无疑是创新的,但也带来了问题:题目的准确性、清晰性和科学一致性未能得到充分保障。研究团队指出,HLE在题目评审环节给出的时间和审核深度限制导致许多题目没有经过严格的科学验证。尤其是审阅人员仅需用五分钟进行初步审核,且不强制验证所有论据的准确性,使得一些“陷阱式”或“曲解性”问题得以通过审核最终入库。以化学领域为例,HLE中的一个示例题——“2002年地球上最稀有的惰性气体是哪一种?”的答案竟是“oganesson(鿫)”,这引发了广泛质疑。鿫是一种人工合成元素,在2002年仅存在极短时间并极其罕见,不属于地球自然丰度统计范畴。
此外,最新研究表明鿫并不真正表现为传统意义上的惰性气体,反而在物理化学性质上更接近固态且具较高反应活性。此类错误答案不仅误导了模型训练和评估,也会影响科学知识传播的准确性。生物学科同样存在问题。题库中关于蛇蛉目昆虫是否摄食花蜜的题目说明了这一点。HLE给出的答案是肯定的,但相关领域的权威文献表明迄今尚无可靠记录显示蛇蛉成虫有采食花蜜的习惯,这意味着答案与现实观察存在较大出入。这些事实反映出HLE题库和答案之间的科学矛盾,并由此引发了对评测有效性的质疑。
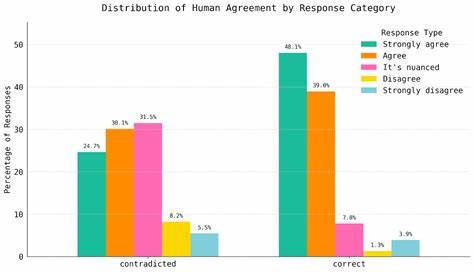
研究团队利用自主开发的文献查询和事实核查AI工具Crow,深入挖掘了超过300道HLE化学生物题目的相关文献支持情况。结果显示超半数的答案和推理存在文献不支持甚至直接矛盾的情况。由独立专家参与的二次人工评审进一步验证了这一发现,认为约三分之一的题目存在答案有效性问题。这样的发现引发了对AI评测设计哲学的反思:在追求更高难度和前沿性的同时,如何确保科学依据的准确性和题目的可验证性?科学界本身具有不确定性和复杂多变的特性,前沿研究往往存在不同观点和矛盾证据。这一现实使得设计完美且客观无歧义的考试困难重重。HLE的案例正好展现了科学前沿的动态面貌及评测标准的局限性。
值得庆幸的是,HLE的创作团队已经注意到这些问题的严重性,并与质疑方进行了积极沟通。后续修订版中,HLE将引入更严格的三人专家复审制度,并采用滚动修订和持续完善机制,力求不断提高题库质量,减少答案的争议性。与此同时,像FutureHouse这样专注于科研文献自动化检索与事实验证的企业也推动了AI与科学评测结合的新模式。通过开放资源和社区合作,未来的评测不仅要考察模型解决复杂问题的能力,也将重视答案的科学依据和透明度。对于正在使用或计划使用HLE平台进行模型评估的研究人员与开发者而言,建议关注官方发布的“Bio/Chem Gold”子集,该数据子集经多方验证,具备较高准确度和科学合理性,是更可靠的评测选择。此外,HLE事件提醒整个AI与科学界重视知识准确性的重要性。
AI模型作为智能助手或研究工具,不应仅被训练为“考试机器”,而需具备对知识源的深度理解与核实能力。如何在快速发展的AI技术与科学研究之间找到平衡,将成为推动科学进步和技术革新的关键课题。归根结底,《人类最后的考试》中化学生物答案被质疑的现象,是一次对当前AI评测框架的警钟。它促使我们重新审视科学评测的设计理念,唤醒对知识严谨性的坚持,也展现了人类智慧和机器智能共同成长的曲折路径。未来的评测工具需要在挑战极限与科学诚信之间找到合适的结合点,从而为AI研究注入真正可靠且具有指导意义的动力。随着AI技术不断演进,我们期待更完善、公正且反映真实科学共识的评测体系,助推人类探索科学奥秘的脚步迈上新台阶。
。