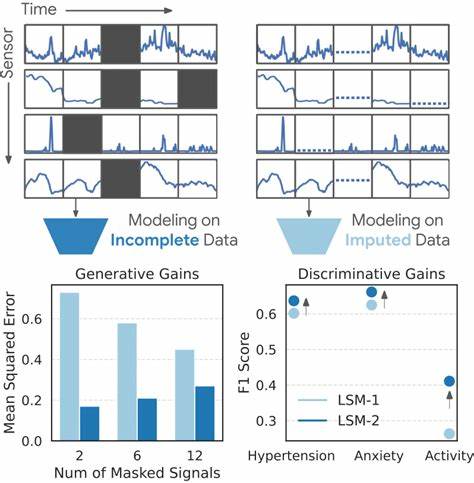
随着智能穿戴设备的普及,人体行为和生理数据的连续监测成为可能,极大地促进了个性化健康管理的发展。心率、睡眠、压力指标和活动水平等多模态数据的采集,为用户提供了前所未有的健康洞察。然而,真实世界中的穿戴式传感器数据往往存在缺失,这一现象因传感器设备取下、充电、松动、运动干扰、电池节能模式及环境噪声等因素而普遍存在。大量缺失数据仍然是阻碍穿戴技术与人工智能深度结合的主要挑战之一。传统的机器学习方法通常依赖完整数据,缺失片段需通过插补或剔除不完整数据进行处理,这不仅可能引入偏差,还浪费了宝贵的数据资源。为了应对这一难题,谷歌研究团队于2025年7月发布了革命性的LSM-2模型,携手Adaptive and Inherited Masking(AIM)自监督学习框架,开创了无需填补缺失值、直接从不完整穿戴传感器数据中学习的新时代。
LSM-2以其卓越的性能,成功适应了现实数据的不连续性,显著提升了分类、回归及生成任务的表现,开启了穿戴技术的全新篇章。Adaptive and Inherited Masking作为LSM-2的核心技术,巧妙地联合了固定比例的人工遮掩与自然缺失的无序遮掩策略。该方法基于掩码自编码器(MAE)预训练框架进行延展,训练过程中不仅模拟人为缺失的信号进行重构学习,还保留穿戴设备天然存在的缺失段作为“固有遮掩”,使模型在面对实际穿戴数据的不规则缺口时,能够稳健应对。这一创新设计,打破了传统自监督学习对完整数据的依赖,提升了预训练的效率和泛化能力,确保LSM-2即使在碎片化数据中依然能够捕捉身体信号的内在联系。谷歌利用超过60000名参与者、共计4000万小时的匿名化穿戴设备数据,进行了大规模训练,为模型注入了丰富的多样性与普适性。这些数据涵盖了来自Fitbit和Google Pixel智能手表及追踪器的生理及行为传感信号,辅以受试者自行报告的性别、年龄和体重等元数据。
在预训练阶段,LSM-2通过AIM技术,将天然缺失和人为遮掩的数据段同时纳入训练流程,学习隐含的时序结构及缺失特征。在下游任务中,模型被应用于各种健康指标与行为识别,包括二分类的高血压和焦虑症判定,20类体育及日常活动分类,以及体质指数(BMI)和年龄的回归预测。评估结果显示,LSM-2在分类准确率、数据重构误差和回归相关性方面均超越先前的LSM-1模型,证明其在现实传感环境下的卓越性能和鲁棒性。尤其在模拟传感器故障、全天数据丢失等极端场景中,LSM-2仍保持较高的输出质量,表现出对数据缺失的抵抗力明显优于基准模型。这表明其更适合多样化的穿戴硬件配置和用户使用习惯,能够灵活适配实际应用需求。此外,LSM-2随着数据量和模型规模的增长,性能持续提升,尚未出现饱和现象,显示出强劲的扩展潜力。
大规模预训练构建的基础模型具备广泛适用性,能够为医疗监测、运动健康、心理状态评估等多领域提供可信赖的智能支持。LSM-2的开发不仅推动了穿戴设备数据科学的前沿,还为后续的健康人工智能产品奠定了坚实基础。技术背后,AIM的双重掩码机制展现了对复杂传感数据实际情况的深入理解。通过动态调整掩码策略,模型学会区分自然缺失与人为遮掩,避免了盲目填补数据带来的误导,同时维持了输入序列的计算效率。此举保障了模型能够处理任意长度和缺失模式的时间序列,极大提升了预训练稳定性和应用广度。在隐私保护方面,谷歌团队充分考虑了用户数据安全,所有数据均通过去标识化处理,并且受试者明确同意数据的研究用途,确保伦理合规。
这使得大规模真实环境数据得以安全用来打造强大的AI系统,极大促进了科学研究的可信度和透明度。LSM-2的成果对于未来智能健康生态系统的构建具有深远意义。它代表了一种新的范式:不再回避、不再依赖完美数据,而是充分利用数据本身特性,提升模型对复杂现实世界的理解能力。该技术潜力巨大,能推动远程医疗、个性化运动指导、慢病管理等多种场景的智能化升级,提升用户体验和健康收益。综上所述,LSM-2以其创新型的自监督学习方法和强大的拥抱缺失数据能力,树立了穿戴式传感器数据处理的新标杆。未来随着更多数据汇集、更复杂的模型设计及更广泛的应用探索,LSM-2及其后续版本将进一步赋能数字健康领域的智能变革,带来更精准、更便捷、更可信的健康管理服务。
。