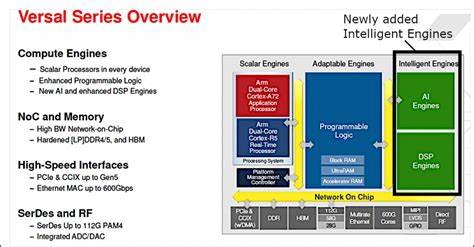
在现代人工智能与机器学习不断迅猛发展的背景下,硬件平台的选择与设计成为制约性能发挥和应用推广的重要因素。现场可编程门阵列(FPGA)凭借其高度可定制化和并行处理能力,成为AI推理和加速的重要解决方案。尤其是集成了专门针对AI任务优化的AI引擎(AI Engine,简称AIE)的FPGA系统设计,为实现高效能、低功耗的智能系统提供了全新途径。本文将深入探讨FPGA中AI引擎的系统设计方法,聚焦AMD的Versal架构及其配套的软件平台Vitis,分析从软硬件协同设计到部署运行的完整流程。首先,全面了解AI引擎作为FPGA内的专用计算单元,其设计定位和优势至关重要。Versal FPGA中的AI引擎是一种高度集成的异构计算资源,内置专用的图形化处理单元,支持流水线式数字信号处理和机器学习算法。
这些AI引擎不仅能够处理海量数据,还可与FPGA中的传统逻辑电路和处理系统(如ARM核)实现无缝协同,极大提升整体系统性能和能效。整体系统设计首先需要基于目标应用和开发板(如VCK190)的硬件特点,选择合适的开发工具链。AMD提供的Vivado设计套件和Vitis统一软件平台构成了兼容Versal器件的关键软件基础。用户通过Vivado完成基础硬件平台搭建,创建包含处理系统(PS)、网络芯片交换(NoC)、AI引擎和AXI接口等模块的FPGA设计,奠定硬件架构基础。随后,利用Vitis Sub System(VSS)设计子系统,则聚焦于软硬件协同的进一步开发。VSS由定制的寄存器传输级(RTL)模块、高级综合(HLS)核和AI引擎内核组成,允许开发者将复杂的算法以IP核形式封装,简化系统集成过程。
设计完成后,将VSS编译生成Vitis Metadata Archive(VMA)文件,实现与Vivado平台的无缝结合。通过这种反向导入流程,可以在Vivado里对整体设计进行细粒度的性能调优和资源分配优化,最大化硬件利用率。时钟管理和中断配置是设计中不可忽视的环节。基于Vivado自动生成的包含多个频率时钟资源(最高可达500MHz)和丰富中断连接的设计环境,Vitis Linker能够协调各IP和AI引擎的运行节奏,确保系统稳定高效。除此之外,借助Vitis IP支持的内存映射转流接口,实现数据通路的灵活配置,为AI引擎核心提供连续高效的数据流,满足神经网络推理或数字信号处理的低延迟、高吞吐要求。软件层面同样关键。
基于由PetaLinux构建的嵌入式Linux操作系统,开发人员可在FPGA处理系统上部署定制应用,实现对AI引擎的控制和数据交互。利用Vitis平台创建的PS应用可以直接调用AI引擎加速核,完成推理计算,从而实现从硬件加速到应用调用的闭环,提升开发效率。应用部署方面,通过自动化make命令,完成从Vivado平台搭建、VSS子系统创建、VMA导出到最终的软件打包与SD卡映像制作,实现一键部署。用户只需将文件复制到SD卡并插入VCK190评估板,即可快速启动系统,验证AI引擎的功能和性能。与此同时,在实际应用中,FPGA AI引擎设计不仅限于AI或机器学习领域,还广泛扩展到数字信号处理、多媒体处理等领域,展现出其通用性和灵活性。Versal架构下的AI引擎支持多种编程模型,使开发者可以根据需求自定义流水线和并行处理策略,有效降低延迟并提升实时处理能力。
总结来看,FPGA中AI引擎的系统设计是一项复杂而系统的任务,需要软硬件协同优化,涵盖从底层硬件平台创建、IP核设计、系统集成、软件开发到最终应用部署的完整流程。AMD Vitis统一软件平台和Vivado设计套件提供了强大支持,帮助开发者有效管理复杂度,实现灵活高效的智能系统搭建。未来,随着AI算法的不断创新和对边缘计算性能需求的提升,FPGA AI引擎设计将持续发挥核心作用。同时,开发工具链的不断演进也将推动AI引擎设计更加智能化、自动化,为嵌入式AI应用带来更大潜力和价值。 。