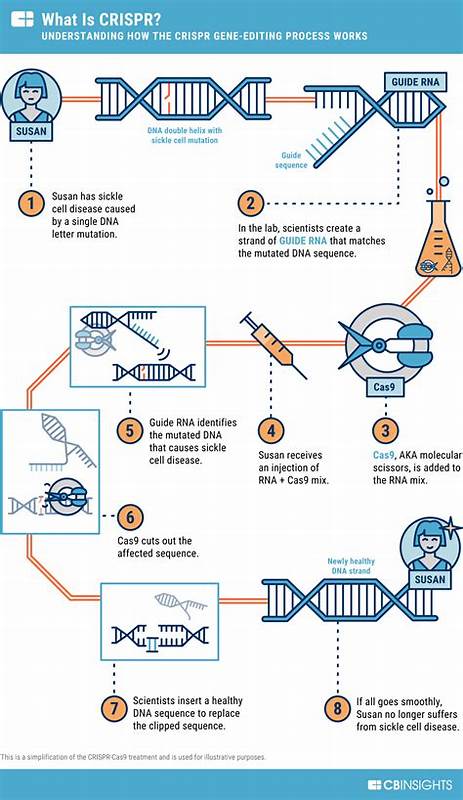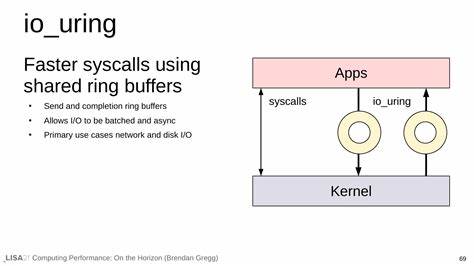
在讨论 Linux 高性能 I/O 的演进时,人们常常把 io_uring 与 select、poll、epoll 等"事件系统"并列,甚至把它视为它们的下一代替代者。表面上看,io_uring 也能处理多路 I/O 问题,但把它仅仅理解为一种更快的事件通知机制,会大大低估它的设计初衷与潜在影响。io_uring 的真正价值在于它不是单纯的事件系统,而是一个通用的异步系统调用设施 - - 它把"请求执行某个操作"这一步交给内核处理,从而避免用户态频繁参与,降低上下文切换与系统调用开销。 要理解这种差别,首先需要回顾传统的 I/O 模型。经典的阻塞式系统调用(例如 read)会让线程在内核中睡眠,直到所需条件满足;多路复用设施(select、poll、epoll、kqueue)则提供了"描述符就绪"的通知机制,也就是说用户态先询问"哪些描述符可读或可写?",接着再针对那些就绪的描述符发起实际的 read/write 系统调用。这个流程中,用户态会做两次内核交互:一次用于注册或等待事件,一次用于执行 I/O。
对于高并发、高吞吐的场景,这两次交互本身会造成可观的开销。 io_uring 的思路是把这两步合并想象为"提交一个我想做的操作,然后等待完成结果"。用户态将要执行的操作(例如 read、write、open、fsync 等)以结构化的请求(SQE)写入到内核可以访问的提交队列(Submission Queue),内核在条件满足时直接执行这些请求,并在完成队列(Completion Queue)中回填结果(CQE)。通过内存映射的环形缓冲区、批量提交与批量完成,io_uring 大幅减少了系统调用和上下文切换的次数,从而在延迟和吞吐上带来显著提升。 把 io_uring 看成一个"远端 API"或者"异步系统调用代理"会更贴切。它允许应用程序把要做的事情描述给内核,然后可以继续做别的或是等待批量完成。
相比之下,事件系统回答的是"哪里发生了事情",而 io_uring 回答的是"请在合适的时候替我把事情做完"。这两个范式在实现细节与编程模型上都不同,也会影响到程序结构的设计、错误处理策略和性能调优手段。 从工程实践角度看,io_uring 的优势体现在多个方面。首先,它打破了传统上对文件 I/O 异步化的限制。历史上 Linux 的 aio 支持有限且难用,很多文件系统操作始终只能在阻塞模式或用户态线程池里实现异步。而 io_uring 为文件 I/O 提供了统一的异步接口,允许内核直接完成大量文件相关操作或者将其交给内核工作线程处理,以更高效的方式返回结果。
其次,io_uring 支持批量化提交和完成,这对减少系统调用开销、提高缓存友好性和降低锁竞争非常有利。再者,io_uring 提供了注册固定缓冲区(fixed buffers)、注册文件描述符(registered files)、SQPOLL(内核轮询提交)等功能,这些特性在极端性能需求场景下能进一步挤出延迟和 CPU 消耗。 不过,io_uring 并非万能钥匙。要实际获益,需要考虑内核版本与特性支持、文件系统与驱动的兼容性、以及应用的 I/O 模式。例如,一些文件系统或内核实现并不能对所有操作实现真正的异步行为,内核可能会在后台为你排队并使用工作线程来完成某些看似异步的请求,这在性能分析时需要识别。SQPOLL 模式能把提交也交给内核,从而避免用户态频繁的系统调用,但它会在内核中占用 CPU 来轮询,需要权衡 CPU 使用与延迟要求。
注册文件与缓冲区能减少内核态与用户态的参数拷贝,但编程复杂度也随之上升。 在采用 io_uring 的实践中,理解提交队列(SQ)和完成队列(CQ)的工作模型非常重要。应用将一系列 SQE(Submission Queue Entries)写入 SQ,内核在适当时机调度并执行,结果以 CQE(Completion Queue Entries)形式写回 CQ。这个模型天然适合流水线化和批量化场景,例如高并发网络服务器可以把一系列读写操作一起提交给内核,内核完成后应用再统一处理结果,从而减少用户态的轮询或阻塞等待。 在语言生态与库支持方面,io_uring 的兴起也推动了多种语言的适配。C 的 liburing 提供了直接接口,允许精细控制 SQE/CQE 的使用;在 Rust 生态里,tokio-uring 等项目试图把 io_uring 的高性能与 Rust 的异步生态整合,但必须处理好安全性与所有权问题。
Go、Java 等语言社区也在探索如何将 io_uring 与各自的运行时融合,特别是在网络框架、数据库驱动与文件处理库中,io_uring 提供了重写热点路径以获得明显性能收益的机会。 对于开发者而言,采用 io_uring 时应注意几个关键实践点。合理使用批量提交与完成可以获得最显著的性能优势;同时要设计好错误处理与超时策略,因为请求提交后可能在内核中延迟执行或被取消;利用固定缓冲区和文件注册可以降低拷贝与参数打包的开销,但在实现上要小心内存管理和并发访问;对 SQPOLL 等高级特性要做严格的基准测量,因为它们对不同硬件和负载的影响相差很大。 在具体场景中,io_uring 表现尤为出色的包括高性能 HTTP/Web 服务器、反向代理、数据库存储引擎、日志收集与批量文件传输等。其中网络 I/O 的优势来自于减少系统调用与内核切换,而文件 I/O 的优势在于内核可以更直接地完成异步读写并减少用户态轮询。对于流媒体、实时通信或低延迟交易系统,io_uring 能减少尾延迟并提高整体吞吐,是值得投入工程时间重构关键路径的技术。
从运维与调试角度看,io_uring 带来了新的可观测点与挑战。传统的跟踪工具和性能剖析器需要适配 io_uring 的队列模型,开发者应使用支持 io_uring 的追踪工具(例如 perf、bcc、bpftrace 等社区工具逐步加入了相关可观测性)来诊断延迟缘由与资源瓶颈。同时应关注内核队列深度、SQE/CQE 的积压、SQPOLL CPU 占用、注册缓冲区的内存使用等指标。错误模式也会不同:例如提交失败、完成结果为 -EIO 或者被强制在工作线程中执行,这些都需要在应用层被识别与处理。 安全与兼容性也是不可忽视的问题。io_uring 通过内存映射的环形缓冲区实现高效交互,这要求程序正确处理并发访问、内存屏障和缓存一致性问题。
不同内核版本对 io_uring 的实现与特性支持不同,部署时要保证目标环境的内核版本足以支持所需的功能集合。另一个现实问题是容器环境与受限权限场景,部分 io_uring 特性在默认容器配置下可能不可用或需要额外的内核参数与权限设置。 长期来看,io_uring 不仅仅是一个性能优化工具,更可能驱动应用架构的重新思考。传统的事件驱动模型中,用户态需要频繁检查"哪些描述符就绪",而 io_uring 则鼓励以声明式的方式描述"我要做什么",让内核在条件允许时代为执行。这样的思路在复杂服务端程序中具有天然优势:减少不必要的用户态调度、避免重复的系统调用开销,并将更多的 I/O 管理逻辑下放给内核或专门的工作线程,从而让应用以更少的指令完成更多工作。 总之,把 io_uring 简化为 select/epoll 的加速版,是对它能力的误读。
io_uring 更接近于一个高效的异步系统调用代理,它改变了"谁来执行 I/O 操作"的范式,提供了一套能够更好地支持文件和网络 I/O 的通用接口。对于需要极致吞吐与低延迟的系统,io_uring 提供了强有力的工具集;但要充分发挥其潜力,需要理解底层模型、评估兼容性、并在代码与部署上做出相应调整。随着内核持续演进与生态工具链的完善,io_uring 有望在未来几年内成为构建 Linux 高性能 I/O 应用的重要基石。 。