在当今数字化时代,数据已成为企业最重要的资产之一。然而,伴随着数据规模的快速增长,数据处理的复杂性与成本也居高不下。传统的数据仓库、ETL工具及分析平台往往价格昂贵且功能分散,给企业带来了沉重的维护负担和操作难度。近年来,开源技术如DuckDB的出现为数据处理带来了变革性的机遇。基于此,Summer公司凭借对DuckDB技术的深刻理解和创新应用,完成了700万美元的融资,力图将DuckDB融入数据栈的每一层,打造首个端到端的DuckDB驱动数据堆栈。Summer的愿景是让数据处理变得愉悦且高效,彻底破解数据堆栈中价格高企和工具割裂的难题。
Springboard DuckDB 背后的强大技术基础 作为一种嵌入式列式数据库,DuckDB因其简洁的设计、高效的查询性能和跨平台能力,而迅速成为数据工程和分析领域的宠儿。与传统依赖于大型分布式集群的数仓系统不同,DuckDB通过单机运行即可提供接近甚至超越分布式系统的查询效率。同时,它具备开箱即用、零运维成本和灵活扩展的优势,尤其适合数据科学家、开发人员和企业快速构建轻量级数据解决方案。DuckDB还支持WebAssembly,使得数据处理可以直接在浏览器中高效执行,拓宽了数据应用的边界。Summer正是看中了这些优势,决定围绕DuckDB打造从数据抽取、转换加载(ETL)、数据仓库到分析的全套工具,实现数据处理流程的无缝衔接。 Summer完成700万美元融资:加速数据堆栈创新 Summer公司最新完成的700万美元种子轮融资由RRE领投,多家风投基金和天使投资人参与。
资金到账后,Summer迅速扩大技术团队与产品开发进度,正式发布了首个端到端DuckDB驱动的数据栈产品。这一产品覆盖数据的多个关键环节,不仅整合了ETL、数据仓库及分析功能,更提供了统一的用户体验和高性能保障。Summer期望通过强大且经济高效的工具,降低企业使用复杂数据系统的门槛,促进数据驱动决策的普及。 Summer颠覆数据产业痛点:价格、复杂与割裂 在传统数据体系里,用户往往面临令人望而却步的费用账单,频繁更换工具,以及庞大的运维压力。不同供应商的产品往往难以无缝衔接,企业需要花费大量时间进行系统集成和维护。Summer的目标是打破这一格局,以DuckDB技术为核心,构建一体化的解决方案,大幅降低数据堆栈整体成本。
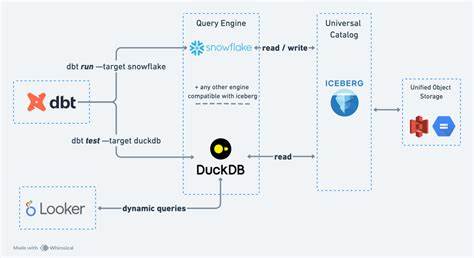
由于DuckDB无需依赖外部集群和复杂配置,Summer的产品极大简化了部署流程,快速响应企业业务需求变化,从而提升整体数据操作体验。 Summer数据堆栈核心组成及应用场景 Summer推出的第一版数据堆栈主要聚焦于ETL、数据仓库和分析三大模块。ETL环节使用DuckDB的高速数据处理引擎,实现数据的快速清洗、转换和加载。数据仓库模块保证了安全存储与高效查询,为复杂分析提供坚实基础。分析层集成灵活的查询接口和可视化工具,支持业务人员和数据科学家深入洞察数据价值。此端到端架构减少了数据迁移和格式转化的成本,极大提升了数据流转速度和整体效率。
该解决方案适用于金融、互联网、零售等多个行业,助力企业实现数据资产的最大化利用。 开源与社区驱动力:Summer与DuckDB生态共建 Summer不仅将核心技术基于DuckDB打造,还积极支持开源社区的发展。通过发布开源组件和工具,Summer希望汇聚更多开发者和用户的力量,共同完善数据堆栈生态。开放的技术透明度和创新氛围有助于推动数据工具的持续进步,并保障用户享有灵活选择权。与此同时,Summer通过举办技术分享会和构建Slack社区,加强用户间交流,快速响应市场反馈,加速产品迭代。 未来展望:从DuckDB协议到更广泛的数据愉悦体验 Summer创始团队深知,数据技术的真正革命不只在于单一组件的提升,而是生态系统的整体进化。
DuckDB作为底层协议的潜力巨大,为多样化数据应用提供统一标准。Summer将继续扩大技术研发,探索数据治理、目录管理等更多领域的创新,将DuckDB优势渗透至数据全生命周期管理。借助其领先的性能与灵活性,Summer期望构建一个无缝、高效且易用的未来数据世界,让用户不再被繁琐的数据基础设施所困扰,而是专注于数据价值创造。 总结 Summer的700万美元融资不仅体现了市场对DuckDB及其相关创新的高度认可,也标志着数据堆栈变革的加速到来。通过深度整合DuckDB技术,Summer为传统数据处理领域注入全新活力,打破数据管理的高成本和复杂性障碍。未来,伴随着技术持续完善和生态壮大,Summer有望引领行业迈向一个更轻松愉快的数据时代。
无论是数据工程师、分析师还是业务决策者,都将在Summer的数据栈解决方案中找到更便捷、高效的工作模式,从而释放数据的全部潜力。