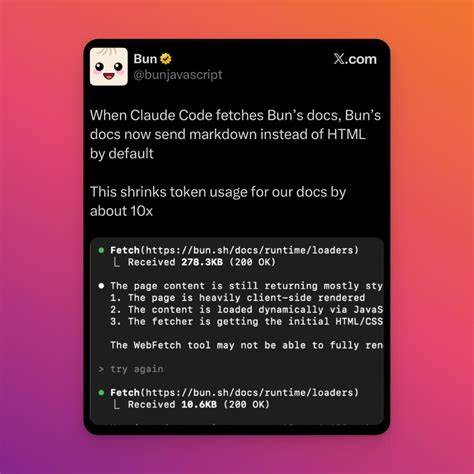
引言 在面向大规模语言模型(LLM)或者像 Claude Code 这样的代码生成与理解模型提供文档时,选择以 Markdown 格式而非传统的 HTML 提供页面,能带来一系列优势:简洁可解析的文本、保留语义结构的同时降低噪音、更便于模型识别代码块与示例。Bun 作为新兴的高性能 JavaScript 运行时,其内置的 HTTP 服务能力和极快的文件 I/O,使得在服务器端直接把 Markdown 文档作为原始响应体交付变得既简单又高效。本文将从实际操作、技术细节、性能与安全、以及与 Claude Code 交互的优化角度,完整讲解如何在 Bun 中实现并部署 Markdown 文档服务。 为什么要把文档以 Markdown 而不是 HTML 提供给 Claude Code Claude Code 等模型在处理文档时更依赖结构化但简洁的标记。HTML 虽然能表现丰富的样式和交互,但同时带来大量标签、类名、脚本和样式噪音,增加了模型在解析时需要忽略的无关信息。Markdown 本质上是文本优先的标记语言,天然强调段落、标题、代码块和列表的语义,便于 LLM 抽取关键信息、识别代码示例和保留原始格式。
此外,Markdown 文件通常比等效的 HTML 文件体积更小,传输更快,且更容易进行差异比较与版本控制,这对持续集成和文档审阅流程非常友好。把 Markdown 原样提供,也能避免浏览器渲染对模型处理的干扰,确保 Claude Code 得到更干净、更一致的输入。 Bun 的优势与适配点 Bun 的设计初衷是兼顾开发者体验和运行时性能。它内置了高速的 HTTP 服务器、原生的打包器和对文件系统的极低延迟访问,这使得直接读取 .md 文件并以文本形式响应成为理想选择。Bun.serve 提供了简洁的 API,用于快速搭建静态或动态文档服务。通过设置合适的响应头,可以明确告诉客户端或 LLM 文档的媒体类型(text/markdown),同时利用压缩和缓存机制保证大并发下的响应效率。
Bun 对现代 JavaScript 特性有很好的支持,便于在同一进程中实现路由、缓存逻辑、权限校验与日志收集。 如何在 Bun 中实现 Markdown 文档服务(核心思路) 基本流程是:接收请求、解析路径与查询参数、定位对应的 Markdown 文件、读取文件内容、设置合适的 Content-Type 和缓存相关响应头、可选地对内容进行最小化或注入元数据,最后将 Markdown 作为响应体返回。实现过程中要考虑路径安全(避免目录遍历)、缓存策略(ETag/Last-Modified/Cache-Control)、压缩(gzip 或 Brotli)、以及针对 Claude Code 的特殊头部或协商策略。 示例实现(伪代码,方便移植) const fs = require('fs'); const path = require('path'); Bun.serve({ port: 3000, fetch(request) { const url = new URL(request.url); let docPath = decodeURIComponent(url.pathname); if (docPath === '/' || docPath === '') docPath = '/README.md'; const base = path.resolve('./docs'); const fullPath = path.join(base, docPath); if (!fullPath.startsWith(base)) return new Response('Not allowed', { status: 403 }); try { const stat = fs.statSync(fullPath); if (stat.isDirectory()) return new Response('Not a file', { status: 400 }); const body = fs.readFileSync(fullPath, 'utf-8'); const headers = new Headers(); headers.set('Content-Type', 'text/markdown; charset=utf-8'); headers.set('Cache-Control', 'public, max-age=60'); const etag = 'W-"' + stat.mtimeMs + '-' + stat.size + '"'; headers.set('ETag', etag); return new Response(body, { status: 200, headers }); } catch (e) { return new Response('Not found', { status: 404 }); } } }); 上述示例展示了最基本的实现思路。实际生产环境中应增加错误处理、异步读取、内容压缩以及针对大文件的流式传输。 请求协商与 Content-Type 的选择 为了让 Claude Code 和其它客户端明确知道接收到的是 Markdown,需要设置 Content-Type: text/markdown; charset=utf-8。
部分客户端或代理可能更喜欢 text/plain。当你希望在同一端点同时为人类浏览器呈现 HTML 页面并为 Claude Code 提供 Markdown,可以实现内容协商:检测请求头中的 Accept 或特定的自定义头(例如 X-Requested-From: claude-code 或 Accept: text/markdown)。如果客户端明确接受 text/markdown,则返回 Markdown;如果是浏览器且接受 text/html,则可以返回将 Markdown 渲染为 HTML 的结果或重定向到静态站点生成的 HTML 版本。 示例头部协商逻辑(伪代码) const accept = request.headers.get('accept') || ''; const preferMarkdown = accept.includes('text/markdown') || request.headers.get('x-llm') === 'claude-code'; if (preferMarkdown) return respondWithMarkdown(); return respondWithHtmlOrRedirect(); 通过自定义头进行显式声明,是与 LLM 集成时较稳健的方案,因为很多 LLM 请求是经过代理或 SDK 发出的,能控制请求头更可靠。 缓存与性能优化 针对文档服务,合理的缓存策略可以极大提升响应速度并减少磁盘 I/O。推荐做法是结合 Cache-Control、ETag 与 Last-Modified。
静态 Markdown 文件通常在版本发布时变更,因此设置短期的 edge 缓存并配合长缓存的 CDN 可以兼顾即时性与效率。对于频繁更新的文档,使用弱 ETag(W-)或基于文件修改时间与大小的哈希作为 ETag,允许客户端使用 If-None-Match 发起条件请求,服务器返回 304 减少带宽占用。 在 Bun 中可以结合内存缓存(有失效策略)与文件系统监控(fs.watch 或构建时刷新缓存)来减少同步读取。Bun 的高性能 I/O 已经在许多场景下表现优秀,但对高并发需求,使用 CDN 缓存原始 Markdown 或将 Markdown 转换后托管到对象存储仍是常见做法。 压缩和传输优化 将响应体启用 gzip 或 Brotli 压缩能显著降低传输体积。Bun 本身支持对往返进行压缩的中间件或由反向代理(如 Cloudflare、NGINX)负责压缩。
在直接由 Bun 处理压缩时,需要检查请求头中的 Accept-Encoding 并针对不同文件大小和 CPU 权衡选择合适的压缩算法。对于小型 Markdown 文件,启用压缩几乎没有额外开销;对于超大文档,建议配合流式压缩以避免占用过多内存。 代码块、语法高亮与 Claude Code 的兼容性 Markdown 中的代码块使用 lang 标记语言种类。对于 Claude Code 来说,保留代码块的语言标签非常重要,这有助于模型推断语境与期望的输出语言。因此不要移除或转换这些语言标签。不要将代码块中的特殊字符实体化为 HTML 实体,因为那样会增加解析难度并破坏原始代码格式。
若需要对代码做额外处理,例如插入行号或注释,尽量提供原始 Markdown 的副本,或通过元数据(header frontmatter)来描述额外信息,而非直接修改代码块内容。 安全与内容净化 直接提供 Markdown 有助于避免 XSS 问题,因为不会把未经清洗的 HTML 直接注入到页面中。但在一些场景中,Markdown 文件本身可能包含嵌入式 HTML。为了避免把危险的 HTML 交给浏览器或模型前端,需要在返回 Markdown 之前做安全审查。对于面向 LLM 的纯后端响应,这一风险较小,但如果同一内容还会在浏览器端渲染为 HTML,必须使用可信的 Markdown 渲染器并对嵌入的 HTML 进行白名单或完全禁用。 另外,路径回溯攻击与私有文件暴露是常见问题。
务必在解析请求路径时使用路径规范化和白名单机制,确保只能读取指定文档目录中的文件。认证与授权也需要在入口处处理,尤其是当文档包含企业内部或受限信息时。 与 Claude Code 的集成建议 为了让 Claude Code 更好地消费 Markdown 文档,建议在请求中显式设置媒体类型。通过 SDK 或代理发送请求时,带上 Accept: text/markdown 或自定义头部表明意图。提供结构化元数据可显著提高检索效率与回答质量,例如在 Markdown 文件开头使用 YAML frontmatter 提供字段:title、tags、version、last_updated。Claude Code 能更容易地依据这些元数据进行上下文选择或索引。
此外,考虑到模型的上下文窗口限制,若文档过长,应在服务端实现片段化(chunking)策略:按章或按节切割 Markdown,并在响应中包含导航元信息与用于重新组合的片段标识符。这样 Claude Code 可以只请求相关片段,避免浪费上下文并提高检索速度。 工作流与自动化 将 Markdown 文档作为主源(single source of truth)能简化内容管理流程。建议在 CI 流程中加入文档语法检查、链路检查以及元数据校验。每次文档变更后自动触发构建流程,将最新的 Markdown 同步到 Bun 服务器或推送到 CDN。若网站还提供 HTML 渲染前端,可以把渲染过程作为可选步骤:在 CI 中生成静态 HTML 以便浏览器端使用,而 Bun 继续提供原始 Markdown 以便 LLM 消费。
日志、监控与调试 对文档访问进行细粒度的日志记录有助于分析 Claude Code 或其他代理的使用习惯。记录的关键项包括请求路径、Accept 头、返回的 Content-Type、响应时间和缓存命中率。结合 APM 或自定义监控,可以发现热点文档并对其进行预缓存或优化。对 4xx/5xx 错误进行告警,及时处理路径配置或权限错误。 常见问题与误区 有些团队误以为把 Markdown 原样返回就能解决所有 LLM 上下文问题,但忽略了文档碎片化、元数据不足或文档内部依赖关系,这些都会导致模型检索效率低下。同样把 Markdown 交给浏览器直接渲染而不处理嵌入 HTML 也可能带来安全问题。
务必根据用户类型区分输出格式,并在需要时提供可下载、渲染或片段化的多种查看方式。 结论与实践建议 把文档以 Markdown 格式直接交付给 Claude Code 在许多场景下是更合适的选择。它为模型提供了更干净的语义输入、降低了解析噪音并简化了版本控制。Bun 提供了实现这一目标的高效平台,通过合理配置响应头、缓存、压缩与安全机制,可以在高并发环境中稳定提供服务。实际部署时建议把 Markdown 作为主源码,结合 CI 自动化、元数据标准、片段化策略和明确的内容协商规则,既能满足模型的消费习惯,也能兼顾浏览器端的渲染需求。通过规范化的工作流和监控,可以实现面向 LLM 的文档服务的长期可维护性和高效性。
附加资源与下一步 如果希望将现有的 Markdown 文档库平滑迁移到 Bun 提供的服务中,第一步是建立文档索引并为每篇文档生成标准化的 frontmatter 元数据。第二步在测试环境验证 Accept 头与自定义头的协商逻辑,确保既能为 Claude Code 返回纯净的 Markdown,也能为普通用户提供渲染后的 HTML。第三步配置 CDN 缓存与 ETag 策略以提升响应速度。按照这些步骤,可以把 Bun 的性能优势与 Markdown 的语义性结合,打造面向 Claude Code 的高质量文档服务。 。









