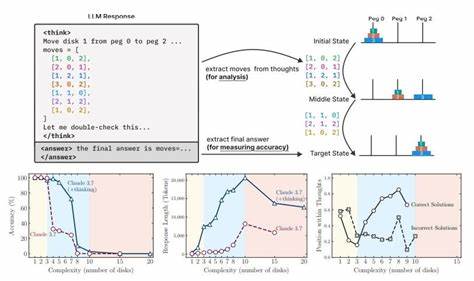
近年来,人工智能领域的飞速发展吸引了全球的高度关注,尤其是在通用人工智能(Artificial General Intelligence,简称AGI)的研发上备受期待。AGI代表着机器具备类似人类的理解、推理和学习能力,能够在多种任务中实现灵活适应和自主思考。然而,苹果公司的最新研究表明,尽管大型语言模型(LLMs)如OpenAI的ChatGPT和Anthropic的Claude等在语言生成和特定任务的表现上取得了显著进展,但它们在真正意义上的推理能力方面仍存在显著不足,距离实现AGI的目标还有相当长的路要走。 苹果的研究团队在一篇名为《思考的错觉》(The Illusion of Thinking)的论文中指出,当前主流的人工智能模型虽然能够处理大量信息并生成似乎合理的答案,但这些模型并未真正理解其回答的逻辑和背后的推理过程。研究者通过设计多种复杂的谜题游戏,对包括Claude Sonnet、OpenAI的o3-mini和o1以及DeepSeek系列模型进行了测试。实验结果显示,在面对更高复杂度的推理任务时,这些大型推理模型(Large Reasoning Models,LRMs)表现出明显的准确率崩塌,无法有效地应用明确的算法进行计算,其推理过程表现出高度不一致,更谈不上达到通用人工智能所需的稳定和通用性。
在很多测试案例中,这些模型出现了所谓的“过度思考”现象——即模型在早期阶段能够给出正确答案,但随着推理步骤的推进,答案逐渐偏离正确路径,展现出不稳定且表层的推理特征。这种现象反映了当前AI模型“模仿推理模式”的本质,而非真正内化和运用推理原则。换句话说,尽管AI可以生成“看似合理”的回答,但缺乏全面且深层次的理解与推理能力,难以实现跨任务、跨领域的通用智能。 苹果的研究质疑了当前主流AI评测方法的有效性。现有评测通常侧重于数学和编程等领域的“最终答案准确率”,忽视了模型在达成答案过程中推理的连贯性和逻辑性。这种评测方法可能掩盖了模型在推理深度和通用能力上的根本缺陷。
研究团队强调,未来的AI性能评估体系需考虑中间推理步骤的正确性和稳定性,才能更全面地反映人工智能的认知水平。 这些发现引发了业界对通用人工智能实现时间表的重新审视。此前,OpenAI和Anthropic等公司的领导层曾对AGI的实现表示乐观,预测未来数年内AGI将成为现实。例如,OpenAI CEO萨姆·阿尔特曼曾表示,他们“有信心知道如何构建传统意义上的AGI”,而Anthropic CEO达里奥·阿莫德伊预测AGI将在2026至2027年间超越人类能力。然而,苹果的最新研究提醒人们,距离真正能够进行人类级别推理和思考的AGI仍有明显的技术鸿沟和理论难题需要攻克。 技术层面,当前大型语言模型主要依赖基于海量数据训练的统计语言生成方式,缺少明确的符号推理和逻辑规则引入,导致其在面对复杂推理任务时表现不稳定。
许多研究者提出,应融合符号AI与深度学习技术,发展更具解释性和可验证性的推理机制,推动AI从“模式匹配”向“真实理解”转变。此外,增设多模态学习、因果推理和自我监督学习等方法,有望提升AI模型的推理深度和泛化能力。 伦理和社会层面,AGI的实现也意味着对人类社会结构、经济模式和政策制定带来深远影响。对AI能力的过度乐观可能导致监管滞后和技术滥用风险增加,因此科学家、企业和政府需要共同推动负责任的AI研发和应用,确保在技术进步的同时保障社会公正与安全。 总的来看,苹果研究团队的成果不仅厘清了当前AI推理能力的真实水平,也为未来AGI的发展指明了方向。实现真正意义上的通用人工智能,需要在基础理论、模型架构以及评测手段等方面进行系统性的突破。
伴随着全球范围内大量研究力量的持续投入和跨学科的深入合作,AGI的梦想虽然仍需时日,但其实现路径将变得更加明晰和务实。 未来,人工智能将在智能助手、医疗诊断、科学研究、教育培训和智能制造等众多领域发挥更加重要的作用。理解和克服现阶段AI在推理能力上的局限,有助于推动技术演进,打造更加智能和可靠的系统,为人类社会的繁荣与发展注入新动力。苹果的研究提醒我们,AGI的实现不只是技术竞赛,更是一场需要耐心与智慧的长跑,我们期待这一领域在未来数年中继续蓬勃发展,为人类开启全新的智能时代。









