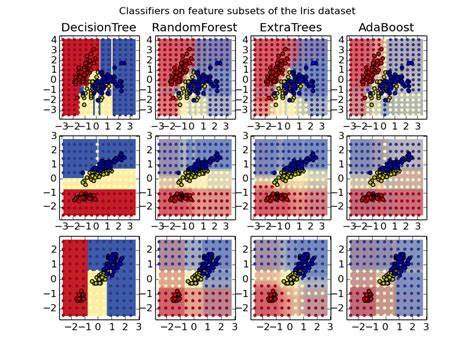
在机器学习领域,算法的选择往往决定了模型的性能和最终效果。虽然市场上涌现了许多新兴的高级算法,如深度神经网络、提升树(Boosting)等,但随机森林依然以其独特的优势,成为众多数据科学家和机器学习从业者的首选工具。自由自在地处理多样化数据类型,简便的训练过程,强大的泛化能力,让随机森林拥有了“非凡效能”的美誉。随机森林最初由统计学大师Leo Breiman提出,作为集成学习方法的一种,它由大量决策树组成。每棵树在训练时从数据中随机抽取样本和特征,使得整体模型能够大幅降低单棵树过拟合的风险,从而提升预测的稳健性和准确度。随机森林的最大魅力之一在于其对输入数据的适应性。
无论是二元变量、类别变量还是连续数值型特征,随机森林都能直接处理,免去了数据归一化或标准化的复杂预处理步骤。这为实际业务场景中多样化且复杂的数据环境提供了极大便利。另一方面,随机森林具备天然的特征自动选择能力。通过评估各特征对模型预测的贡献度,可以有效识别数据中最重要的变量,这不仅提高了模型的解释能力,也有助于后续的数据降维和优化。而且,训练随机森林模型的过程通常非常迅速,尤其在大规模数据集中,子采样特征和样本的随机策略非常高效地降低了计算复杂度。许多情况下,训练一个性能足够的随机森林所需时间远短于诸如深度学习模型或梯度提升树的复杂调参过程。
随机森林的稳健性也是其广受青睐的重要因素。即使模型参数没有经过复杂调优,只要选用较多的树数量,通常都可以得到相当不错的预测结果。这种参数敏感度较低的特性极大降低了初学者和非专家的使用门槛,使其成为了理想的基线模型和性能衡量标准。同时,随机森林作为一种通用算法,适用于回归和分类问题,甚至可以辅助聚类分析。它在处理多类别分类问题时表现尤为优秀,还能给出较为准确的概率预测,从而使模型判断更具信心和可靠性。值得一提的是,随机森林的简洁设计和易于实现,使得几乎所有主流机器学习平台都提供了开箱即用的高质量实现,如R、Python的scikit-learn以及Weka等,极大方便了开发者的集成和应用。
更进一步,随机森林非常适合并行计算架构,因为各树的训练相互独立,可以利用多核处理器和分布式系统快速构建大规模模型,显著提升性能和效率。尽管随机森林优势众多,但也存在一些局限性,其中之一便是模型体积庞大。训练数百甚至数千棵决策树后,模型存储消耗会非常高,评估速度相对缓慢,不适用于对实时响应要求极高的场景。另一个被批评的地方是模型的“黑箱”特性。因为随机森林是众多决策树的集合,整体结构复杂,难以像单棵决策树那样直观解释具体的决策路径,这在某些对解释性要求严格的领域成为劣势。不过,随着各种特征重要性评分方法和可解释性技术的发展,随机森林的透明度正在逐步提升,解释模型行为和获取业务洞察正变得更加容易。
在实际应用中,无论是在金融风险评估、医疗诊断、图像分类还是文本分析,随机森林都展现出了非凡的效果。它不仅提供了强大的预测能力,还因其对异常值具有较强的鲁棒性,帮助用户应对数据中固有的噪声和不确定性。总结来看,随机森林凭借其简单却高效的设计理念,以极低的预处理需求、多样化的适用场景、稳定的预测性能,逐渐成为机器学习领域不可替代的经典算法。即使在新技术层出不穷的今天,随机森林依然以“非凡的效能”在众多算法中占据重要位置,助力数据科学家打造高质量的智能模型。在未来,随着计算硬件的不断升级和算法研究的深入,随机森林有望融合更多创新技术,进一步提升性能及应用广度。无论你是机器学习入门者,还是资深的数据科学专家,深入理解随机森林的本质及其应用之道,将为你搭建稳固的技术基础,开启数据驱动的创新之门。
。