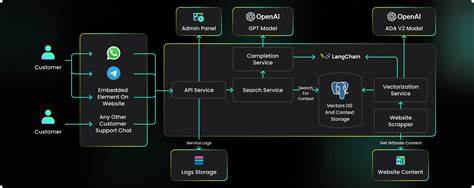
llms.py 已成长为一款轻量且功能丰富的本地 ChatGPT 风格界面与 OpenAI 兼容聊天服务器,适合需要隐私、离线存储和混合本地与云端模型策略的开发者与研究者。它以极少的依赖(仅需 aiohttp),提供浏览器端的现代 UI 与一个兼容 OpenAI API 的本地端点,从而把本地模型和付费云模型统一在同一个熟悉的聊天界面中。对于追求简单部署、数据保密与灵活扩展的人群来说,llms.py 是值得一试的解决方案。版本 v2.0.24 在可观测性、成本分析與使用体验上都有显著增强,适合希望监控消耗、优化支出的团队与个人使用者。你可以通过 pip install llms-py 安装,并用 llms --serve 8000 启动界面与 API,默认 UI 位于 http://localhost:8000,OpenAI 兼容的聊天端点则在 http://localhost:8000/v1/chat/completions。 核心设计理念是简单、私密与兼容。
UI 采用现代浏览器的 JS Modules,无需 npm 或复杂构建流程,这让前端轻量、启动快速,并且将所有对话数据保存在浏览器的 IndexedDB 中。由于浏览器数据与域名和端口绑定,你可以通过在不同端口运行多个实例来实现独立的对话数据库。对话历史、系统提示和配置文件都可以导出和导入,方便跨设备备份和迁移。与许多在线服务不同,llms.py 不含跟踪、广告或强制云同步,所有数据默认保留在本地,隐私保护非常直观。 配置与集成极为灵活。主要配置文件位于用户目录下的 ~/.llms/,其中 llms.json 用于定义 OpenAI 兼容的提供者和模型,ui.json 则包含系统提示库与 UI 默认设置。
系统提示库可扩展,内置数百条专业级 system prompts,用户可以按需添加、删除或重新排序。提供者配置支持优先级与启用/禁用开关,运行时可以动态调整,系统在调用模型时会按配置顺序尝试可用提供者,若某个提供者失败则自动回退到下一个,从而实现高可用的混合策略。对于想在 ComfyUI 等项目中嵌入的开发者而言,llms.py 仅依赖 aiohttp 的特性使其非常易于整合,避免了 Python 环境中依赖冲突的常见问题。 v2.0.24 的一大亮点是全面的可观测性和成本透明化。模型选择器现在会显示每个高级模型的输入与输出每百万 token 成本,消息层级展示每条消息的 token 数量,线程级别的统计会汇总单个会话的总成本、输入与输出 token、请求数量与响应延时。月度成本分析和 token 分析页面可以按天查看消耗明细,并进一步展开以展示具体模型与提供者所产生的费用与 token 使用。
活动日志(Activity Log)则记录了每次请求的模型、提供者、部分提示、输入输出 token、成本、响应时间与速度等信息,且活动日志与聊天历史相互独立:你可以清空聊天历史而保留活动日志,或反之亦然。此外,导出活动日志可以通过在导出按钮上按住 ALT 实现,导出的日志可被随后导入以便进一步分析。 多模态输入与响应是 llms.py 的另一个重要功能。界面支持图片、音频与文件上传,并能对有视觉或音频能力的模型进行处理与分析。图片可以用于视觉理解或图像问答,音频可以上传并由多模态模型进行转录与分析,文档与 PDF 支持批量处理、内容抽取与摘要,适用于研究、审阅与数据提取等工作流。UI 对 Markdown 与代码语法高亮有良好支持,消息与代码块悬浮时提供复制代码图标,提高了从 AI 响应中复用内容的效率。
为了便捷交互,用户还能对任意用户消息进行编辑或重发,这在需要微调提示或重复实验时非常有用。 成本控制與混合模型策略是实际部署时的关键考量。llms.py 支持将免费本地模型与付费云模型混合使用,默认优先启用免费或本地提供者,随后才使用付费云端服务。模型选择器所显示的每百万 token 成本,以及线程与消息级的成本统计,便于用户在对话过程中实时评估支出并做出调整。为了最大限度降低费用,建议把高频率、低成本的任务放在本地或免费 tier,只有在需要更高质量或专门能力时再切换到付费模型。对于需要精确计费的场景,可以结合请求日志与月度分析页面,找出高消耗请求并对提示或模型使用策略进行优化。
运维与可靠性方面,llms.py 提供了检查提供者可用性的命令行工具,便于排查配置或网络问题。可以用 llms --check PROVIDER 来批量检测某个提供者上配置的模型,也可以指定具体模型进行单独检测,例如 llms --check groq kimi-k2 llama4:400b gpt-oss:120b。项目还提供了一个 test-providers.yml 的 GitHub Action,用于周期性测试所有配置提供者的响应时间,并将结果发布到 /checks/latest.txt,供用户查看不同提供者与模型在真实网络条件下的表现。遇到调用失败或超时时,这类检测工具能快速定位是配置问题、凭证失效还是网络延迟导致。 安全与部署建议对于把服务暴露在局域网或互联网的用户尤为重要。默认情况下 llms.py 是一个本地服务,强烈建议不要直接暴露到公网而不做额外保护。
可以通过反向代理(例如 nginx 或 Caddy)添加 HTTPS 与基础认证,或者在需要远程访问时使用 SSH 隧道或 VPN。对于团队内部部署,建议配合公司级身份验证与访问控制策略,限制 API 端点的访问范围。数据备份方面,定期导出对话历史与活动日志并安全保存可以防止浏览器清理或设备故障导致的数据丢失。 对于开发者而言,llms.py 的 OpenAI 兼容端点使得现有依赖 OpenAI API 的工具和脚本可以无缝迁移或并行运行。任何能向 /v1/chat/completions 发送 OpenAI 风格请求的客户端,都能以最小改动接入 llms.py 后端。这种兼容性也便于构建自定义自动化工作流、集成测试或在 CI 环境中复现真实请求。
若需要在生产环境中提升吞吐量或响应稳定性,可以考虑在前端与后端之间引入缓存层、限制并发请求、或为高并发场景预热本地模型。 排错经验来自社区与实际部署案例。常见问题包括提供者凭证配置错误、本地模型路径不对、CORS 或防火墙阻止浏览器访问 API、以及浏览器 IndexedDB 达到配额导致无法保存历史。遇到凭证问题应首先检查 ~/.llms/llms.json 中的 key 值,并使用 llms --check 命令验证提供者连通性。浏览器访问问题可通过在本机使用 curl 或 Postman 调用 /v1/chat/completions 来确认服务端是否正常响应。IndexedDB 导出功能在迁移或备份时非常有用,若迁移到新设备需通过 UI 的导入功能恢复历史记录。
最佳实践包括合理管理系统提示库、将常用、易复用的 system prompts 保存在 ui.json 中以便团队共享,利用活动日志寻找高成本请求并在提示层面进行精简或拆分,以及结合月度分析制定模型使用策略。对于需要链式推理或可解释性的工作,启用对推理过程的渲染有助于理解模型内部思路并促进模型提示工程优化。若追求轻量化部署与低运维成本,借助 llms.py 的单依赖特性并使用本地硬件或免费提供者,可以快速搭建具有良好隐私保护的 AI 聊天平台。 总之,llms.py 将现代浏览器的轻量前端、OpenAI 兼容的本地 API 与丰富的可观测性功能结合在一起,形成一个适合实验、个人使用和小规模团队的高效工具链。无论是需要在本地处理敏感数据、构建混合模型策略,还是希望实现对消耗与请求的精细监控,llms.py 都提供了实用的功能与可操作的配置。通过合理的部署、安全加固与使用策略,用户可以在保证隐私与成本效益的同时,享受类似 ChatGPT 的交互体验并充分利用多模态模型的能力。
想要快速体验的用户可以用 pip install llms-py 安装并运行 llms --serve 8000,然后在浏览器中打开 http://localhost:8000 开始探索本地化的智能对话世界。 。




![围绕《Imagine with Claude: build working software and UI on the fly [video]》展开,解析生成式人工智能如何在设计、编码与测试环节实现即时交付,探讨开发者与产品团队应用方法、效率提升点与潜在风险](/images/EAFB7FA7-5C4B-40BC-9F58-704A6737778C)



