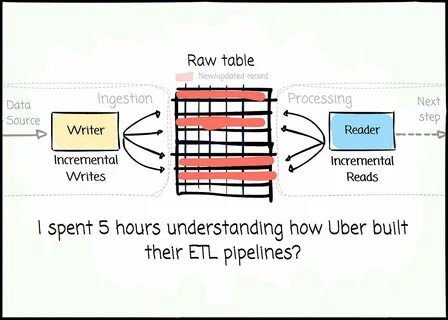
随着数据量的急剧增长和业务场景的复杂多样,企业对数据处理能力的要求也不断提高。作为全球领先的出行服务平台,Uber面对海量实时数据,如何构建高效可靠的ETL管道成为业内关注的焦点。经过长达五小时的深入研究发现,Uber的数据工程实践并未简单依赖传统的批处理或流处理管道,而是采用了创新的架构设计,融合了多种技术优势,提升了数据处理的效率、灵活性和准确性。 首先,传统的ETL流程大多分为批处理和流处理两大类。批处理通常适用于大规模数据集的周期性刷新,优势在于处理效率高、技术成熟,但缺乏实时性。流处理能实时响应数据变动,支持快速决策,但面临处理复杂度高、数据一致性保证难等挑战。
Uber深入思考后,发现单纯依赖其中一种方式难以满足其业务对数据时效性和准确性的双重要求,于是探索了全新的ETL构建路径。 Uber采取了一种融合多种处理机制的混合架构,既避免了传统批处理的延时问题,也克服了流处理的一些局限。在该架构中,数据的捕获和初步处理实时进行,以保证业务系统能够快速获取最新信息。同时,通过增量更新和事件驱动的模式,系统能够灵活调整数据处理的粒度和频率,提升整体准确性和资源利用效率。这种架构核心基于Uber自行研发的技术工具,例如基于Lambda架构思路的自定义平台,以及高度自动化的作业调度和监控系统,确保数据流程的稳定运行和异常快速响应。 技术栈方面,Uber不仅使用了开源大数据组件如Apache Hadoop、Spark、Kafka等,还在此基础上进行了深度定制和优化。
Kafka作为消息队列的核心被用于实时数据的捕获和分发,支持高吞吐量和低延迟。Spark承担了复杂的批量和流式数据处理任务,Uber的工程师们通过调优计算资源分配和内存管理,最大限度地提升了处理性能。此外,Uber引入了自主研发的调度系统和数据编排工具,自动化执行ETL作业,实现端到端的数据流动无缝衔接。 在数据质量管控上,Uber同样设立了严格的标准和自动化流程。实时数据流经过多层校验和过滤,异常数据能够被及时检测和隔离,防止对下游数据分析和业务决策造成影响。数据血缘追踪技术则帮助团队对数据来源和变化路径进行追踪,提升整体数据透明度和可维护性。
这些措施有效确保了数据管道的稳定和可信,满足业务对精确数据的需求。 从架构设计可见,Uber强调模块化和可扩展性,面对业务增长和新需求时,可以轻松地扩展计算资源,提升处理能力。系统采用微服务风格,解耦不同环节,提高了开发和维护效率。工程团队密切合作,持续进行系统性能优化和新功能迭代,保证平台技术能够快速响应市场和业务变化的节奏。 除了技术层面的突破,Uber在数据文化建设上也体现出前瞻性的思考。团队重视数据工程师的技能升级和协作,推广最佳实践和文档化,促进知识共享和技术传承。
通过举办内部技术分享、培训和hackathon,鼓励创新和问题解决能力的提升。从而保障ETL管道不仅在技术上先进,也在团队执行力和响应速度上领先行业。 整体而言,Uber的ETL管道建设不仅突破了传统数据工程的局限,更树立了行业的技术标杆。通过融合批处理与流处理优势,打造高度自动化和灵活的数据处理平台,实现了数据传输的高效、稳定和精准。这一创新实践为数据工程师提供了宝贵的借鉴经验,尤其在应对复杂实时业务场景和大规模数据挑战时,展现出了卓越的价值和潜力。 未来,随着人工智能、机器学习等技术的逐步成熟,Uber的数据工程系统也将持续进化,进一步挖掘数据价值,支持更智能的业务决策和用户体验升级。
对于广大数据从业者来说,深入理解Uber的ETL设计理念和实现细节,有助于开拓视野,提升自身专业能力,为迈向更高水平的数据工程之路打下坚实基础。