随着人工智能技术的持续进步,光学字符识别(OCR)与检索增强生成(RAG, Retrieval-Augmented Generation)在文献数据处理领域发挥着越来越重要的作用。尤其是在学术论文等高质量文献的应用场景中,精准地解析与利用表格信息成为提升自动问答及知识检索准确性的关键因素。本文将详尽分析OCR和RAG技术在表格处理中的难点及创新实践,聚焦如何有效结合上下文信息,推动复杂PDF文档的智能理解与应用。 首先,学术论文作为知识密集型的文献载体,常常呈现出多栏目、多样式的复杂版面设计,尤其在STEM领域,不同形式的表格、图表成为承载重要数据的典型表现。PDF作为学术传递的主流格式,虽然具有良好的视觉排版效果,但其内部结构复杂且多样,缺乏统一的机器可解析的语义结构,给自动化处理造成了极大阻碍。传统的文本提取方法很难完整且准确地获取表格数据,更遑论表格所在的上下文环境信息,从而导致后续检索和生成环节的误差和偏差。
OCR技术的持续演进为解决这一难题提供了重要工具。近年来,基于视觉语言多模态基础模型(VLMs)的OCR技术展现出较强的图像与文本联合理解能力,能够将PDF中的图像元素有效转译为结构化的Markdown格式表格。这种转译不仅使数据更利于后续自动处理,也提升了表格内容的可读性和解析度。然而,尽管VLMs在OCR领域取得显著进展,它们依然面临诸多挑战,尤其是无法自动识别复杂的文档阅读顺序、多栏文本的断裂,以及表格与其标题、图例分离造成语义信息缺失的问题。 表格在文档中的识别和处理并非单纯提取文字内容那么简单。比如,同一页上连续出现的多个表格,其对应的标题和说明往往不与表格内容紧密关联,成为独立的文本块。
缺乏标题和说明的联系,直接影响信息的准确获取和解读。举例来说,一个关于某技术性能指标的表格,若无法识别其"表3:某季度性能指标"这样的标题和说明,后续问答系统在匹配查询时极易误判,导致产生无关甚至错误的信息回复。 为此,在构建高效的RAG管道时,将表格的上下文信息(如表格标题、标签)与表格内容一同嵌入至知识库成为关键改进点。通过上下文感知的块处理方式,RAG系统能够在检索阶段更精准定位相关信息,提升匹配的相关性与准确率。根据实验数据,对比仅嵌入纯表格内容的"机械分块"方式,包含上下文信息的"上下文感知分块"方案在F1分数上提升接近40%,精确匹配率也有约33%的增长。这意味着系统能更有效地理解表格背后的实际意义,从而提供更为准确和有价值的回答。
OCR本身面对的技术难题也非常多样。一方面,脚注、页眉、分页等页面元素会破坏文本连贯性,造成"断裂段落",OCR输出的文本层常常夹杂着不连续的信息,难以形成连贯的语义片段。另一方面,多数VLMs基于逐页处理方式,忽略了文档整体的章节层次结构,导致标题层级标注错误或标识混淆。例如,将章节标题错为加粗字体而非标准的Markdown标题标记,进一步影响内容组织与检索效率。 此外,由于VLMs和OCR工具多以视觉渲染为目标,表格中的复杂符号、公式和单元格合并等结构经常识别错误。甚至部分图表被错误识别为普通文本,缺少必要的结构化标签,使得后续解析变得模糊不清。
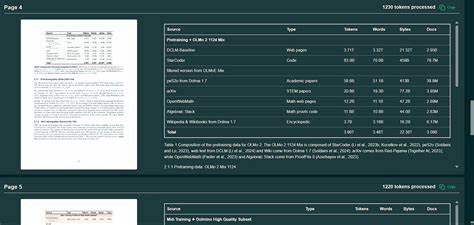
同时,当前尚无通用标准来自动关联表格及其图题,在标注、归档等环节增添不少成本和不确定性。 解决上述问题的理想方法是采用结构化格式输出,如XML(特别是JATS 1.4标准),能够明确嵌套和关联表格内容与元信息。例如,XML格式中,表格包装元素内清晰包含标签与说明内容,使得表格解析器可以直接获取完整的语义信息。可惜现实中文档往往以PDF形式流通,直接获得XML结构的资源稀缺,这也促使研究者和开发者不断完善PDF结构化重建与上下文融合技术。 为评估不同OCR与RAG处理方案对表格理解与问答准确性的影响,研究者们基于"OCR Hinders RAG"公开数据集进行实证分析。该数据集涵盖近50份学术PDF,包含数百个表格相关问答对,明确标注了答案的来源与类型。
通过对比纯粹嵌入表格内容与结合标题说明的两种块处理策略,结果表明上下文感知处理明显优于机械分块,能够显著提升F1和准确率。 这一实验证实,文本处理和信息检索的质量深受OCR初级处理环节的影响。未经加工的PDF在内容理解上的劣势不可忽视,直接导致RAG系统产生错误答案、误导用户乃至降低科研效率。而通过融合上下文,RAG的检索结果可以准确定位到最相关的片段,方便研究者快速验证与参考。特别是在医学等高风险领域,高精度的信息检索和解释机制尤为关键,对患者安全和研究进展具有深远意义。 未来,OCR与RAG技术的协同发展将继续推进,尤其是多模态模型能力的提升将优化视觉与语言信息的融合处理。
同时,探索更智能的文档结构重建方法和上下文关联机制,将有助于实现从原始PDF自动生成高质量、结构清晰的知识库。此外,标准化文档标注及格式转换流程的普及,也是提升全链条准确度的重要保障。 总之,随着VLM和RAG技术在表格处理领域的不断突破,我们有望迎来更加智能高效的知识检索新时代。对复杂文档的OCR水平提升、上下文信息的合理引入以及结构化数据的精准提取,成为驱动自动问答、学术搜索和数据挖掘实现质的飞跃的关键所在。掌握和运用这些先进技术,不仅提升了研究工作的效率,更助力于推动科学发现与技术创新迈向新高度。 。