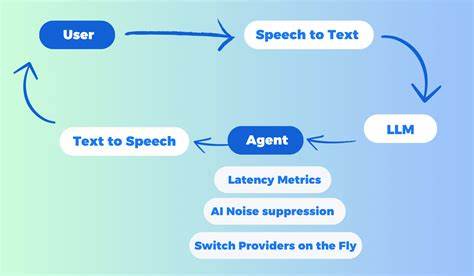
随着人工智能技术的不断进步,人机交互方式也在持续演变。尤其是在自然语言处理领域,大型语言模型(LLM)如OpenAI的GPT系列、Mistral等不断刷新着人们对智能对话的认知。然而,尽管文本对话已经极大地提升了智能助手的实用性,语音交互的流畅性和实时性依然是制约用户体验的关键瓶颈。Unmute系统正是在这样的背景下诞生,提供了一个突破性的解决方案,让文本LLM能够“听”懂用户语音并“开口”回应,实现真正的实时语音对话。Unmute背后的技术核心是将先进的语音转文本(STT)和文本转语音(TTS)模型无缝融合进语言模型,使整个交互过程自然且低延迟。 Unmute系统架构独特而高效。
用户通过网站界面发起连接,前端与后端之间通过WebSocket实现实时数据流传输,确保语音数据和响应信息的无缝交互。后端则起到枢纽作用,先将接收到的用户语音传送到Kyutai Labs开发的高性能STT服务器,快速精准地将声音内容转化为文本。文本随后传入本地部署或外部API托管的LLM服务器,如VLLM、OpenAI、Mistral等,生成智能回复。与此同时,生成的文本通过Kyuati的TTS服务器实时合成为自然流畅的语音,回传给用户实现即时反馈。整个过程高度优化,保证了从用户说话到机器回应的感知延时极低,提升整体人机交互体验的沉浸感和流畅度。 在硬件配置层面,Unmute推荐使用具备CUDA支持且显存至少16GB的GPU设备,以确保语音识别、语言模型推理和语音合成三个模块协同运行时保持高效性能。
系统支持Linux及Windows下的WSL环境运行,而为了最大化部署便利性和环境一致性,官方极力推荐采用Docker Compose容器化方案。这种方式不仅简化了多服务依赖的管理,且便于快速启动和扩展。此外,Unmute允许多种部署形式:Docker Compose适合单机多GPU场景,Dockerless提供灵活的不依赖Docker体验,Docker Swarm则支持跨多机大规模集群扩展,满足不同规模和需求的用户。 从模型选用上看,Unmute默认使用Mistral Small 3.2 24B模型,既保持了强大的语言处理能力,又拥有较好的运行效率。用户也可以根据需求替换成其它开放模型或者大型API,如Gemma 3、meta-llama等。通过Hugging Face账号进行模型权限认证和访问凭证管理,确保模型调用安全可控。
更灵活的是,Unmute支持无缝集成多种第三方LLM接口,开发者只需修改配置文件即可轻松切换,极大地增强了系统的开放性和扩展性。 Unmute在语音处理方面也展现出不俗实力。基于Kyutai Labs的专属STT与TTS模型,在延迟与质量之间取得了理想平衡。与单GPU部署相比,多GPU协同显著降低了语音合成的响应时间,从约750毫秒缩短至约450毫秒,大幅提升交互自然度。语音识别精准度在多轮对话中保持稳定,为后续语言模型生成打下坚实基础。该优化效果让Unmute无论是用于在线智能客服、语音助手,还是互动娱乐,都表现出极佳的用户体验。
此外,Unmute项目本身具备高度的开源精神和社区支持。官方不仅提供详尽的部署文档和开发指南,还维护多样的工具与调试模式以利于快速迭代开发。用户可以开启开发者模式,实时查看底层调试信息,方便定位问题和优化性能。系统还支持定制多样化角色与声音配置,通过voices.yaml文件统一管理,结合系统化提示词机制,实现个性化的人机语音交互场景构建。此灵活性为产品定制和二次开发提供了丰富土壤。 面对安全挑战,Unmute也有相应对策。
对访问模型的API Key权限进行细致划分,避免不必要的写权限暴露,从而降低潜在风险。同时由于实现了WebSocket与多模块服务间的实时通信,数据流传输设计上注重稳定与安全,尤其在远程访问与端口转发方面均给予明确说明及规范配置,保证用户隐私与系统数据安全。 Unmute不仅在技术实现层面具备前瞻性思维,其生态建设也显示出强大生命力。配合不断迭代的前端交互设计和Web技术栈优化,用户界面日趋简洁友好,支持快捷键开启字幕与调试视图,进一步提升了流畅度和易用性。官方还鼓励社区贡献,如扩展工具调用能力,使得Unmute未来不仅是一个静态的对话系统,更能成为多功能智能助理的基础框架。 总的来说,Unmute作为一套创新的实时语音交互方案,完美融合了尖端的语音模型与大型语言模型技术,解决了以往文本模型只能被动读取与回复的痛点。
它通过优化的系统架构、多样化的部署选项以及对主流语言模型的兼容支持,为开发者与企业带来极大的灵活性和效率提升。在人工智能逐步走入日常生活的趋势下,Unmute开创了让机器“听得懂”且“能说话”的新纪元,助力构建更智能、更自然的人机交流未来。随着生态完善与社区壮大,相信Unmute将在智能语音交互领域持续引领潮流,成为推动人机交互范式变革的重要力量。









