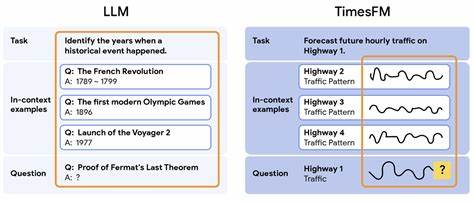
时间序列预测是现代数据科学中的核心任务之一,广泛应用于库存管理、能源需求预测、交通流量监控等众多领域。传统的时间序列预测方法通常依赖于为每项任务专门训练一个模型,这不仅耗时且需要丰富的专业知识,难以适应多变的市场和任务需求。随着零样本学习的出现,这一困境得到了一定缓解。零样本学习允许模型在未经过任务专门训练的条件下,依然完成准确的预测,为时间序列分析带来了革命性的转变。谷歌研究团队此前推出的TimesFM即是一款零样本预训练基础模型,在无需特定任务训练的情况下表现出色。然而,现实中往往存在少量关键数据,如果能够利用起来,预测效果或将大幅提升。
为此,新的研究提出了基于继续预训练的少样本学习方法,使时间序列基础模型能够在推理阶段从少数示例中学习,获得与监督微调同等的性能,而无需用户进行繁琐的训练。该模型被称为TimesFM-ICF(In-Context Fine-tuning),在设计上对原有的TimesFM进行改造,赋予其从上下文中快速适应的能力。核心思想是让模型不仅关注预测序列本身的历史数据,还能参考相关的几个示例数据以辅助判断,同时通过学习如何区分和处理这些不同示例,避免数据混淆。这种区分靠引入了一种可学习的"通用分隔符",起到类似于语言模型中段落分隔符的作用,使模型在注意力机制中能够准确识别不同时间序列块,防止多个数据序列被当成连续数据误读。例如,若将不同商店的销售数据简单合并,模型可能误解为单一波动模式,而借助分隔符,模型能理解这是多条互不干扰的趋势序列,从而做出更准确的预测。在模型结构方面,TimesFM-ICF依然延续了基于Transformer解码器的架构。
时间序列数据被切分成固定长度的"时间点块",作为输入令牌序列,通过堆叠的自注意力层和前馈神经网络进行信息提炼,最后由多层感知机将处理结果转回时间序列格式。相比于以往的预测方式,该方法创新性地将历史数据与示例数据融合输入,利用特殊标记区分,并通过后续的继续预训练过程使模型掌握新的上下文学习规则。此预训练阶段使用包含分隔符和示例的专门构造数据集,基于因果自注意力机制(causal self-attention)实现对历史时序的前向预测严格限制,保证模型预测时不会"偷看"未来信息,从而保持时间序列的时序完整性。谷歌团队对TimesFM-ICF进行了严格的测试,覆盖23个未见过的新数据集,涵盖丰富的实际应用场景。实验结果表明,加入少样本示例的TimesFM-ICF在准确性方面比原始TimesFM提升了6.8%,更重要的是它达到了与针对特定任务进行监督微调后的TimesFM-FT同等的表现。这意味着使用者无需重新训练模型,只需给出少量相关示例即可获得定制化的高质量预测,极大简化了模型应用流程。
此外,研究还发现随着更多上下文示例的输入,模型预测准确率进一步上升,但同时推理时间也有所增加,这符合预期。相比于传统的长上下文模型,TimesFM-ICF在利用示例信息方面表现更有效,提升了模型的适应性和泛化能力。这项创新不仅技术意义重大,更具备广泛实际应用价值。对于企业而言,只需依赖单一强大的时间序列基础模型,通过简单输入相关示例,就能为新产品需求预测、市场变化响应提供精准帮助,避免每次都组建复杂的机器学习项目,显著降低开发成本,提升业务响应速度和竞争力。这促使高端预测技术的门槛大幅下移,使更多用户能够借助智能化工具实现科学决策,推动整个行业的数字化转型。展望未来,研究者们计划进一步完善示例选择策略,实现自动化筛选最相关的上下文数据,使模型在少样本学习中更加高效和智能。
随着模型能力的不断增强,时间序列基础模型有望覆盖更为复杂的场景,包括多变量、高维度及非平稳序列的预测,为数据驱动的世界注入更强大的动力。时间序列预测领域正经历由传统定制模型走向通用基础模型的深刻变革。TimesFM-ICF以其突破性的少样本学习能力,向外界展示了基础模型在应对现实复杂任务中的广泛潜力。凭借其强大的泛化性能和易用性,它引领了时间序列预测的下一代技术方向,未来有望成为支撑智能经济的关键技术基石。综上所述,时间序列基础模型通过引入少样本上下文学习,实现了预测能力的质变。该技术革新打破了以往模型需专门训练的桎梏,将预训练与灵活适应完美结合,赋予模型从有限数据中快速学习的能力。
随着算法与计算资源的不断进步,时间序列预测正迎来更加智能、高效的新时代,助力各行各业实现精准洞察与科学决策,推动数字化浪潮深入发展。 。