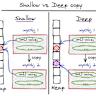
在现代JavaScript开发中,对象的复制操作频繁出现,尤其是在处理复杂数据结构时。深拷贝作为一种常用的数据复制方法,确保复制对象之间互不干扰,极大地避免了程序中由于引用共享引发的错误。理解深拷贝的原理、区别以及实现方式,对于任何JavaScript开发者来说都是必不可少的技能。首先,深拷贝与浅拷贝是两种常见的对象复制形式。浅拷贝仅复制对象的第一层属性,而对象内部的嵌套对象仍然共享同一引用,也就是说,修改嵌套对象的属性时,原始对象和副本都会受到影响。相比之下,深拷贝则递归地复制对象的所有属性,包括嵌套的对象,使得复制出来的每一层结构都完全独立,不存在任何引用上的关联。
这样,当修改深拷贝得到的对象时,原始数据保持不变,避免了数据污染和意外变更。深拷贝的核心概念还涉及对象的结构等价性。两个对象如果不仅属性名称和顺序相同,而且属性值本身也是深拷贝的关系,且其原型链结构也一致,那么它们可以被视作深度复制获得的副本。值得注意的是,深拷贝的目标不仅仅是复制对象本身,更包括它的复杂内部结构和继承链。实现深拷贝的方法有多种。最简单且广泛使用的技巧是结合JSON.stringify()与JSON.parse()。
先将对象序列化成JSON字符串,再解析成新的对象,通过这种方式获得一个全新的对象实例,属性和嵌套结构全部拷贝。尽管此方法简洁且快速,但由于JSON序列化自带限制,比如无法处理函数、Symbol、DOM节点、递归结构以及某些内置对象类型,因此并不适用于所有场景。随着Web平台的发展,结构克隆算法(structuredClone)应运而生,它是浏览器提供的原生深拷贝工具,能够支持更丰富的数据类型,包括错误对象、映射(Map)、集合(Set)及ArrayBuffer等。相比于传统的JSON方法,structuredClone不仅保留了更多类型的完整性,还支持可转移对象的转移操作,提升性能和效率。需要强调的是,structuredClone是Web API的一部分,而非JavaScript语言自身特性,其兼容性依赖于运行环境的支持。除上述原生方法,许多时候开发者需要自定义深拷贝函数以应对特定复杂对象结构的复制。
此类函数通常递归遍历对象的属性,判断类型并分别处理,确保函数、正则表达式、日期对象及特殊对象能够正确复制。自定义深拷贝的难点在于处理循环引用和保持对象原型链,这要求算法具备权衡性能和正确性的设计。深拷贝不仅在纯前端应用中扮演重要角色,在Node.js服务器端、React组件状态管理、Redux中状态不可变性维护以及各种数据持久化过程中都有广泛应用。例如在React中,为了触发组件的重新渲染,经常需要避免直接修改状态对象,而是通过深拷贝创建全新状态,从而保证数据的纯净和组件的响应式更新。理解深拷贝还有助于规避潜在的性能陷阱。深拷贝操作通常较浅拷贝慢,尤其在大规模数据结构上更为明显。
合理衡量是否需要深拷贝,或者结合不可变数据结构(Immutable Data Structures)及持久化数据结构的设计思路,可以有效优化应用性能和资源占用。除了应用层面,深拷贝的技术实现也映射了计算机科学的经典问题,如图遍历、递归、内存管理和数据序列化。培养对深拷贝底层原理的认识,有助于开发者设计更加健壮、稳定且高效的软件架构。总结来看,深拷贝是JavaScript中确保对象数据互不干扰、维护数据完整性的重要手段。通过了解其本质区别、局限性与多种实践方法,开发者可以针对不同业务需求灵活选择最合适的实现方案。无论是利用简单快捷的JSON序列化,还是依赖功能更全面的structuredClone,亦或是自定义深拷贝函数,关键在于理解复制的深度和引用关系对程序行为的影响。
深入掌握深拷贝相关知识,将显著提升代码质量和开发效率,有效避免因引用共享而导致的bug,助力打造更可靠的应用程序。 。