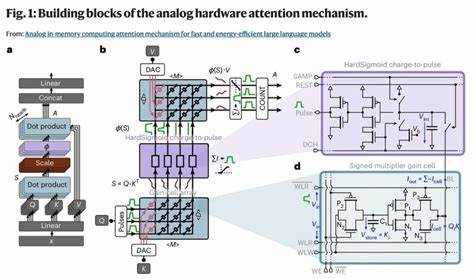
近年来,基于Transformer架构的大型语言模型凭借强大的自然语言理解和生成能力,已广泛应用于翻译、问答、内容生成等多种场景。然而,这些模型在推断阶段对计算资源和能耗的需求极高,尤其是其中核心的自注意力机制。传统方法通过在GPU和SRAM之间频繁传输数据,导致延迟提升和能源消耗增加,制约了模型在实时和边缘应用中的推广。模拟内存计算技术因其将计算与存储深度结合的特性,成为解决这一难题的新希望。模拟内存计算(In-Memory Computing)通过在存储单元内部实现并行的模拟乘加操作,大幅减少数据移动,从而显著降低能耗并提升计算速度。在自注意力机制中,关键计算环节是对先前生成的Token嵌入向量与当前查询进行高维度的点积运算。
本文介绍了一种基于新兴电荷控制型增益单元(Gain Cells)的模拟内存计算自注意力架构,该架构能够高效地将Token信息直接写入内存阵列,同时实现大规模并行的模拟点积,极大提升推理效率。与传统GPU加速方案相比,这种架构在保持文本处理性能接近GPT-2水平的前提下,减少了多达五个数量级的能源消耗和两万个数量级的计算延迟,这标志着生成式Transformer在功耗和响应速度方面实现了质的飞跃。尽管模拟增益单元电路带来了噪声、非线性等硬件非理想性,一些典型的模拟误差限制了其对预训练权重的直接映射利用。文章详述了一种针对这些挑战设计的初始化算法,通过仅依赖初始化而非重新训练,使模型具备了良好的泛化能力,成功发挥模拟硬件的计算潜力。这一策略不仅降低了硬件实现的复杂度,也为未来无缝迁移大规模语言模型到模拟计算平台奠定基础。从系统架构角度看,该模拟内存自注意力机制有效融合了存储和计算资源,弱化了传统GPU计算环境下存储层级间数据传输的性能瓶颈。
这种紧耦合方案适合动态生成任务的Token缓存存储,满足连续推理时序对计算高并发性的需求。与此同时,模拟架构具备极低能耗和低延迟特点,极大提升边缘AI设备及低功耗服务器对大型语言模型的适用性。展望未来,模拟内存计算自注意力机制为大规模深度学习模型的加速设计树立了新标杆。随着硬件工艺的持续进步和算法优化的深入结合,预计该技术将广泛应用于多模态大模型及实时生成等更复杂的人工智能场景,推动AI计算平台向极致能效比和高响应速度演进。综合来看,模拟内存计算的引入为克服大型语言模型推断能耗高、延迟长的难题提供了革命性路径,开启了超高速、低功耗生成智能的新时代。抓住这一技术机遇,将引领AI领域在硬件与算法协同创新上的新篇章,推动智能系统性能发挥到极致,实现更广泛的产业化和应用普及。
。