近年来,Transformer架构引领了自然语言处理技术的革新,赋予了大型语言模型(LLM)强大的理解与生成能力。然而,尽管它们的表现令人惊叹,理解这些模型内部的工作原理仍是一项极具挑战性的任务。Transformer模型的核心 - - 嵌入表示,隐藏着丰富的语义信息,如何揭示这些嵌入中所蕴含的"概念"成为了人工智能研究者关注的热点。近年来,一个已有20年历史的经典算法 - - KSVD(K-Singular Value Decomposition)重获新生,成为深入理解Transformer嵌入的有力工具。本文将详述KSVD算法如何帮助研究者分解复杂嵌入,将抽象的空间转换为更具解读性的"概念向量",并探讨其对AI可解释性领域的深远影响。首先,我们需要了解Transformer嵌入为何难以解释。
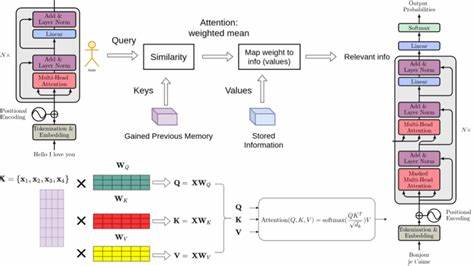
Transformer模型以复杂的高维向量表示输入文本,这些向量融合了大量细粒度的语义和语法信息。人类直观难以解读这些高维空间的结构,也难以辨别某个嵌入究竟表达了哪些具体含义。举个例子,若我们询问模型"Java是什么",模型产生的嵌入可能同时涉及Java编程语言和印度尼西亚的爪哇岛,单凭嵌入的数据本身无法判断具体"想法"。为此,研究者提出了"字典学习"方法,将复杂的嵌入分解成少数更具语义的概念向量,让人工或自动化系统能更好地理解模型内部的抽象思路。字典学习的核心是通过找到一组"概念向量"组成的字典,利用这些元素线性叠加再重建原始嵌入。这里的挑战在于,是否能将高度复杂且信息丰富的嵌入成功拆分成具有单一语义的基础向量。
2022年Elhage等人提出的"叠加假说"提供了理论支撑,指出Transformer嵌入可以视作一系列单义概念向量的叠加。随后,Bricken等人于2023年开创性地将字典学习与模仿神经网络的稀疏自编码器(SAE)结合,用深度学习方法训练隐含概念字典,推动了领域进展。然而,SAE基于梯度下降的优化需要大量计算资源,同时存在对理解是否"过强"的担忧,意味着可能提取出模型本身无法访问的假象特征。相比之下,KSVD算法作为传统字典学习的代表,采用交替优化策略不断迭代更新词典和稀疏编码分配,思路类似k-means聚类,但允许每个样本被分配给多个概念向量。KSVD算法拥有理论成熟、实际应用稳定的优点,然而其经典实现因依赖单步奇异值分解(SVD)计算,导致训练时间极长,甚至需要数十天才能完成一个适合LLM嵌入的字典训练。最近,一项名为"双批量KSVD"(DB-KSVD)的创新极大地提升了该算法的效率,通过算法改进和高效实现,将训练时间缩短至不足十分钟。
这一突破使KSVD再次成为探索大型语言模型内部思想的有效工具。DB-KSVD不仅在运行速度上实现革新,同时在与SAE方法的对比中展现出同等竞争力。通过在SAEBench基准测试中的综合指标表现,包括嵌入重建、特征解耦、概念检测及可解释性等方面,DB-KSVD证明了传统方法依旧具备强大生命力。此结果表明,无论是深度学习驱动的稀疏自编码器还是经典KSVD,两种截然不同的优化策略都能达到接近理论极限的性能,揭示了现有字典学习方法的有效边界。理论探索方面,研究还揭示了字典学习问题的根本规律。可恢复的概念向量数量与样本数量的平方成正比,每个样本中可激活的概念数量与嵌入维度的平方呈正相关。
此外,字典的非相干性(即概念间的相互独立性)直接影响学习质量。这些发现为实际应用提供指导,强调大规模高维数据和丰富样本对于字典学习成功的必要性。字典学习技术不仅限于语言理解,未来有望拓展至机器人视觉、规划任务等多个领域,成为揭示各种复杂模型内部特征和决策逻辑的重要方法。随着更多高质量嵌入模型的问世,相关技术必将迎来爆发式发展。总的来看,KSVD算法的现代复兴丰富了Transformer嵌入解释的技术路径,帮助研究者从数量惊人的高维数据中挖掘出直观可读的语义概念。通过这类方法,我们有望迈向更加透明、可控的AI系统,促进人工智能在实际生产和生活中的深度融合。
未来的研究可以持续优化算法效率,强化对不同领域嵌入的适应性,探索更多维度的语义结构,开启真正理解机器"思想"的新篇章。 。