隨著人工智慧技術的迅速發展,大型語言模型(LLM)在自然語言生成領域展現出前所未有的潛力,特別是在創意故事寫作方面。為了衡量這些模型在故事構建、風格以及元素整合方面的能力,LLM創意故事寫作評測(Creative Story-Writing Benchmark)應運而生。作為該評測系列的最新版本,V3引入了多項革新和改進,旨在更全面、更嚴謹地評估模型的故事寫作水平。本文將深度解析LLM創意故事寫作評測V3的關鍵特色、評測機制和評分規則,同時探討其在當前大型語言模型應用中的意義與價值。 LLM創意故事寫作評測V3自發布以來,引起了業界廣泛關注。該評測著眼於大型語言模型在創意寫作過程中,是否能夠不僅遵循指定的創意簡報,還能創造出引人入勝的文學故事。
每個故事必須有機融入十個指定的關鍵元素,包括角色、物品、核心概念、屬性、動作、方法、設定、時間框架、動機與基調。通過對這些元素的嚴格融合,評測能夠區分各模型在約束滿足度和文學品質方面的差異。 評測過程中,故事長度被嚴格控制在600到800字之間,避免冗長或過短而影響內容品質的問題。每個故事均由多位獨立的評分大型語言模型負責打分,依據包含十八項問題的評分量表進行細緻評估。這些問題中,八項關注故事的敘事技藝與一致性,涵蓋角色深度、情節結構、世界構建、故事影響力、創新性、主題統一性、敘述視角和語言表達質量等方面;而另外十項則聚焦於故事對十個必要元素的有機整合與體現程度。 在評分方法上,LLM創意故事寫作評測V3採用了加權的冪平均數(Hölder mean)作為匯總指標,其中敘事技藝問題佔60%,元素整合問題佔40%。
此種評分方式能更有效鼓勵模型在各維度平衡發揮,避免某一方面的優異掩蓋另一方面的不足。最終,每個故事的得分通過七位不同評分模型的平均得到,模型總體得分則是其全部故事平均分的反映。 評測結果顯示,目前多個頂尖大型語言模型在創意故事寫作能力上均表現優異,其中GPT-5.2(中等推理版本)憑藉其細膩的角色刻畫和故事結構領跑整體排行榜。GPT-5 Pro、GPT-5.1和GPT-5中等推理版本緊隨其後,展現了強勁的敘事一致性和元素整合能力。此外,Kimi K2-0905、Gemini系列以及Mistral Medium 3.1等模型也在評測中獲得了較高的成績,說明多家企業在語言理解和創作方面均取得顯著進步。相對而言,某些開源或較早版本的模型在故事整體連貫性和元素體現上仍存在較大提升空間。
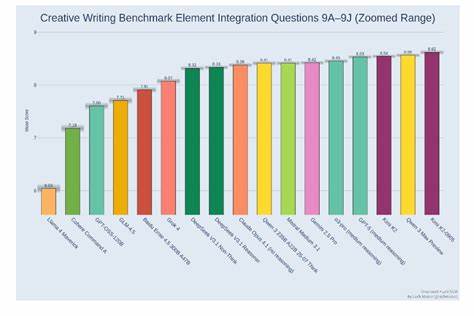
一項重要的觀察是,評分中元素整合維度(即故事是否恰當運用所有指定元素)與故事craft分數(文本品質和敘事結構)保持高度正相關,反映出模型不僅需要符合任務要求,更需將各種元素有機結合,讓故事流暢自然。這種雙重維度的評測機制為未來創意寫作模型的優化指明了方向。 評測進一步通過"逐題細化熱圖"等工具,直觀展現每款模型在不同問題上的表現特點。例如,有些模型在語氣基調和語言風格上表現卓越,但在情節創新和角色動機深度方面略顯不足;而有些模型則擅長按要求整合指定元素,但在故事流暢度及視角統一性上仍有欠缺。這種細粒度分析對模型研發和應用都有深遠影響,促使設計者針對薄弱環節進行針對性改進。 在評測穩定性和一致性方面,V3版本亦進行了多重健壯性檢驗。
比如通過剔除每款模型最弱的故事樣本觀察排名變化,證明了整體排行的穩定性不受個別異常得分影響。此外,針對不同評分模型的相互影響,通過排除某一評分者重新計算后排名變動不大,顯示評分流程科學合理,具備較高的信度。 另一大亮點是評測中對故事長度的嚴格限制和合規性檢查。故事必須嚴格限制在600至800字之間,藉此避免過度填充和內容冗餘,同時保持文本精煉、張力十足。合規性數據與長度分布圖為用戶提供了直觀的合規情況檢查,有利於確保模型不利用字數策略提升分數,而將評價核心放在內容品質。 評測還同步公佈了多個代表性優秀故事範例及相對較差範本,且附帶詳細的元素配置。
一方面,優秀故事彰顯了模型在達成嚴苛元素要求同時,創作出引人入勝並且風格鮮明故事的能力;另一方面,弱勢故事也明確呈現未能合理整合元素或故事框架松散的通病,為模型改進提供直觀參考。 V3版本在技術流程上引入了基於多階段LLM輔助的選題元素生成管道。這一流程從多重大型語言模型生成的候選元素池中挑選出最契合的十個元素組合,從而在每個故事提示裡保證元素的內在一致和合理性。同時,元素類別中最多允許一項為"None",增強了選擇靈活度及故事整體協調性。這樣的管道避免了隨機性過高導致的元素不協同問題,顯著提升了評測標準化和公正性。 除了核心得分和評分機制,V3還增強了數據展示和用戶互動功能。
多維度的評分熱圖、排行榜及模型間的對比分析報告,讓研究者和開發者能夠清晰把握模型優劣和潛在改進方向。此外,評測配合提供的作品及互動式圖表可作為教學和模型調試示例的寶貴資源。 評測的局限性也不可忽視。由於評分完全依賴大型語言模型自身充當評判者,某些主觀性較強的評判標準仍需要人工線下校驗以確認準確性。故事長度嚴格限制雖然方便比較,但未必完全代表理想的文學作品節奏。此外,由於每次提示內只選擇固定十個元素,故事多樣性會受到一定限制,對部分自由創作場景的真實映射存在不足。
這些都是未來迭代需要持續關注的方向。 綜合來看,LLM創意故事寫作評測V3不僅是一項創新性的技術測評,更是推動大型語言模型文學創作能力快速進步的重要里程碑。它以高標準的元素嚴格性和深度的敘事質量分析要求,迫使模型在藝術與技術之間尋求平衡,展現出智能文本生成的全新高度。隨著如GPT-5.2、Kimi K2、Gemini等先進模型的蓬勃發展,未來人機協作創作的場景將變得更加豐富多彩,為文學創作帶來全新視角與可能。 期待未來更多版本能够進一步洗練評測標準,結合人工評價和自動評分的優勢,引入多樣化文體維度,並擴充故事元素種類,為LLM的創意潛力提供更加全面、科學的量化指標。這將不僅服務於技術社群,也將促進文學、藝術與人工智慧的深度融合,推動文化生產力的質的飛躍。
。