随着数字阅读的普及,ePub格式成为电子书的主流标准。许多开发者和数字出版专业人士渴望寻找高效便捷的工具,以便从技术层面深入了解和处理ePub文件。在这方面,ePub-utils无疑是一款不可多得的高效工具。作为一个基于Python的开源库和命令行接口(CLI)工具,ePub-utils允许用户通过终端命令快速解析、检视和提取ePub文件中的各种核心信息,为电子书内容的分析和管理提供了极大的便利。 ePub-utils的核心优势体现在其丰富的功能模块和良好的标准兼容性。该工具不仅支持基本的ePub容器文件和包文件的解析,还能提取关键信息,如书名、作者和标识符等元数据。
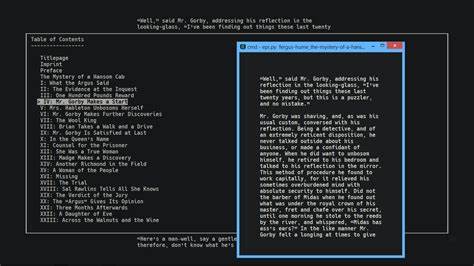
此外,它支持表格内容(toc)、清单(manifest)及目录(spine)信息的展现,极大地满足了电子书内部结构分析的需求。不论是需要浏览原始XML内容、格式化输出,还是以键值对形式查看元数据,ePub-utils均能轻松实现,满足不同层次用户的定制需求。 使用ePub-utils非常简便。安装仅需一条pip命令,便可在任意支持Python的终端环境中快速部署。操作方面,基于命令行的设计不仅使批量处理变得自动高效,也极大地加快了开发与调试流程。以查看容器文件为例,只需简单输入命令即可快速获得完整内容。
结合格式化参数,还能按照用户需求生成彩色高亮的XML输出或纯文本样式,极大提升可读性和分析效率。 此外,ePub-utils对不同的ePub标准提供了全面支持,包括EPUB 2.0.1和EPUB 3.0+版本。对于早期EPUB格式的支持体现在对OPF 2.0包文件、NCX导航控制文件以及Dublin Core元数据的精准解析上;而对于新兴的EPUB 3.x标准,更是涵盖了HTML5内容文档、导航文档(nav.xhtml)、辅助功能增强、媒体覆盖及脚本支持等多项先进特性。这种标准的兼容保障了其广泛适用性,使得无论是传统还是现代电子书格式用户都不会遇到兼容问题。 对数字出版行业从业者而言,ePub-utils不仅是用来浏览文件的工具,更是进行深度分析和自动化操作的重要助手。借助Python库接口,开发者可以将ePub-utils无缝整合至自己的工作流或软件中,自动提取元数据、分析章节内容,甚至进行格式转换和批量管理。
通过编程调用,灵活利用其各类接口与数据结构,大幅度提升了电子书内容处理的效率和准确性。 ePub-utils的命令行功能同样强大,从简单查看文件清单到查看内容片段,都能通过简单直观的命令实现。文件列表命令可以以表格或纯路径形式输出,让用户快速浏览电子书中包含的所有资源。对于具体章节内容,也可选择以高亮的XML形式、原始HTML代码或纯文本格式进行呈现,更好地满足编辑、校对和内容分析的多样需求。 安全性和可靠性也是ePub-utils值得称道的地方。它严谨遵循各项行业标准,确保输出数据符合EPUB官方规范,同时对现实中存在的各种非标准电子书结构也拥有出色的容错机制。
这意味着用户不用担心由于格式不规范导致解析失败,工具可以兼容并适应多样化的电子书版本,保障工作流程稳定顺畅。 用户社区方面,ePub-utils依托GitHub平台积极维护,对用户的反馈和问题响应及时。开源特性使得其不断完善,功能持续丰富,帮助更多开发者和出版工作者应对技术挑战。丰富的文档资源和示范命令也为新手入门提供了良好的支持,降低了学习门槛。 总之,ePub-utils以其强大的解析能力、丰富的命令行功能和兼容多版本规范的特性,成为电子书开发和数字出版领域一款不可或缺的工具。无论是从事电子书制作、内容审核还是技术开发的专业人士,均可借助它快速深入理解并操作复杂的ePub文件格式。
它不仅提升了电子书处理的效率和质量,还推动了数字出版技术的进一步发展。随着未来电子书标准的不断升级,ePub-utils无疑将持续发挥自身优势,成为数字阅读生态中的重要组成部分。