在现代数据分析领域,时间戳(Timestamp)的处理一直是一项复杂而又关键的任务。时间戳不仅关系到数据的准确性,还直接影响分析结果的可靠性。DuckDB,作为一个专为分析设计的嵌入式列式数据库系统,其在时间戳的处理上也存在一些值得关注的问题。深入理解这些问题,掌握有效的应对策略,对于数据库管理员、数据工程师以及分析师来说尤为重要。 首先,时区的处理是引发许多时间戳问题的根源之一。DuckDB支持时间戳带时区(TIMESTAMPTZ)数据类型,这意味着时间戳数据会根据当前设定的时区进行展示或计算。
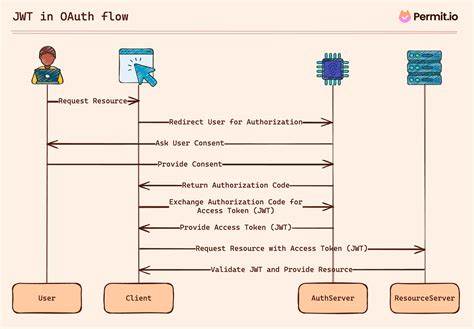
然而,SQL中日期到时间戳带时区的转换规则往往让用户陷入困惑。例如,当用户设定不同的时区后,查询相同的时间戳数据,结果却大相径庭,甚至出现意想不到的空结果集。 具体而言,如果用户将时区设置为"America/Los_Angeles",并创建一张包含2025年8月30日至8月31日每小时时间戳的表,对于查询小于等于2025-08-30的时间点,结果会显示当天0点的时间戳,带有相对应的-07时区偏移。但当时区切换到"夏威夷标准时间(HST)"时,同样的查询结果出现了多条时间记录,均为前一天的时间坐标,偏移量变为-10小时。更令人困惑的是,当时区设为"America/New_York"时,查询竟然返回空结果。这些行为的根源在于SQL内部对日期到时间戳带时区的自动提升规则,其会将日期转换为当天凌晨0时的时间戳,且该时间戳基于当前会话所设置的时区,因此查询条件中的日期边界因时区不同而产生差异。
面对这一困境,一个行之有效的建议是除非需要针对当前时区进行显示或特定的时间分箱(temporal binning)操作,否则应优先选择使用无时区的TIMESTAMP类型存储和计算时间信息。TIMESTAMP类型避免了时区转换带来的复杂性,且其算术计算的效率也更高,能显著降低意外偏差的出现概率。 除了时区转换的复杂性外,DuckDB在时间戳性能方面也面临一定挑战。其采用了ICU(International Components for Unicode)库来支持时区功能,ICU库具备支持2037年以后夏令时规则的优势,相较于诸如Pandas等工具在长远时间范围的时间转换中更加准确。然而,ICU的性能并不理想,在大规模时间序列数据计算时可能成为瓶颈。 为了缓解这一性能瓶颈,实践中推荐创建专门的时间日历表(calendar table)。
例如,若应用场景涉及从2020年到2100年间的每小时用电需求分析,可以预先生成一个包含这些时间戳及其年、月、日、小时分解信息的表。查询时,可通过表连接迅速获得对应的时间分位信息,避免每次都调用昂贵的ICU时间函数。具体而言,利用generate_series函数生成连续的时间戳序列,通过一次性调用date_part函数提取所需的多个时间部分,将计算量和查询复杂度大大降低。 除了上述技术措施,理解SQL时间的区间筛选原则同样重要。SQL中的BETWEEN操作符实现的是闭区间匹配,即筛选范围包含开始时间和结束时间两个边界,但在时间序列分析中,为避免相邻时间区间的重叠与重复计数,通常采用半开区间原则,即包含左边界但不包含右边界。这种方法确保时间分箱的唯一性和连续性,提高数据分析结果的准确性。
因此,在时间戳比较和筛选时应避免使用BETWEEN,改为明确使用小于(<)和小于等于(<=)等操作符组合,保证时间区间具备半开性质。 细致入微的时间戳处理能力对于数据驱动决策至关重要。DuckDB在该领域提供了强大的工具和灵活的操作接口,但用户也需意识到隐藏在时区转换和时间区间操作背后的实际规律和限制。选择合适的时间数据类型、优化性能的建表策略和精准的时间区间筛选条件,是克服时间戳相关难题的关键。未来,随着时间标准和数据库技术的不断演进,DuckDB对时间操作的支持也将更加高效和易用。 综上所述,时间戳问题常常由于时区转换的不明确规则、性能瓶颈以及时间区间筛选的不当使用而导致数据异常或查询结果不符合预期。
借助DuckDB官网文档中的实用建议和社区经验,数据库使用者可以在设计与查询环节中规避这些隐患,提升数据分析的准确度和效率。掌握时间戳深层次的运作机制,是每个面向时间序列数据的开发者和分析师不可或缺的技能。 。