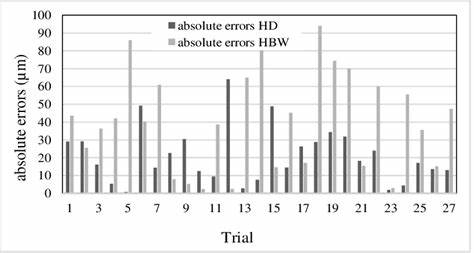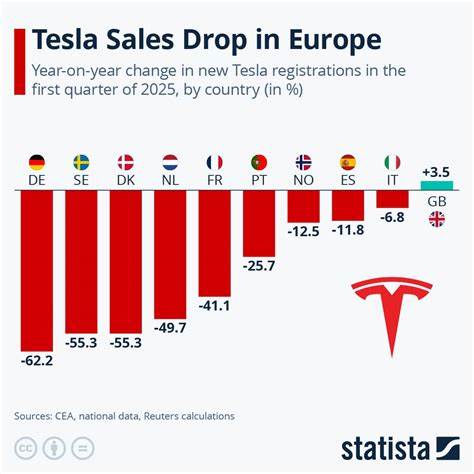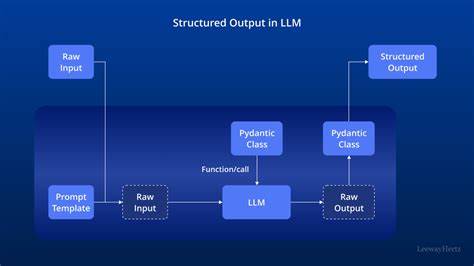
随着人工智能技术的迅猛发展,大型语言模型在自然语言处理各个领域展现了卓越的表现能力。特别是在生成文本的过程中,如何确保模型输出内容不仅准确且符合特定格式,成为关键的研究方向。结构化输出技术正是在此背景下兴起,旨在帮助模型生成具有特定格式和规则的数据,从而更便于后续处理和应用。本文将全面解析结构化输出在大型语言模型中的应用原理、采样机制以及最新的优化策略。 大型语言模型在文本生成的过程中,核心操作是从模型概率分布中采样下一个词元(token)。采样不仅决定了生成文本的多样性和真实性,也直接影响输出是否符合预期格式。
一般而言,模型先经过前向推断得到整个词汇表的概率分布,随后通过各种采样变换来筛选和调整这些概率,从而选择下一个输出词元。这些变换包括topK、温度调节(temperature)、softmax归一化、topP(nucleus采样)和minP采样等。其中,topK保留概率最高的k个词元,显著减少计算量,便于CPU高效执行。温度调节通过调节概率分布的陡峭程度,控制模型输出的创新性与随机性,而softmax则将logits(模型原始输出)转换为概率分布。topP采样选取累积概率达到给定阈值的词元集合,进一步剔除低概率选项,提升采样效率与质量。minP则以最大概率为基准,过滤掉过低概率的词元,兼顾文本的连贯性和创造力。
采样机制虽至关重要,但若不加限制,模型输出容易出现格式错误、语义混乱等问题。结构化输出技术即是在采样基础上引入约束,通过定义格式规则引导模型仅生成符合规范的内容。以JSON结构为例,可以借助形式文法定义数据的有效语法,包括对象、数组、字符串和数字等元素的严格组合。这类文法通过拓扑结构或状态机实现对模型词元的过滤与掩码,屏蔽无效词元,从而保证最终输出一定满足预定格式。 具体到实施层面,结构化输出通常涉及即时语法检查与动态词元约束。模型在每次采样候选词元时,会首先判断其在当前语法状态下是否有效。
如果无效,不接受该词元,而是重新从剩余有效词元概率分布中采样。这种策略保证了格式的严谨性,但不可避免地增加计算开销,因为每个候选词元都需要进行语法合法性检测。为降低复杂度,可以采用利用堆排序等高效数据结构优先筛选topK词元,结合线性复杂度的topP和minP进一步精简采样空间。同时,还可以尝试有限状态机替代纯文法验证,有限状态机在状态转移方面更高效,尤其适合实时高频采样场景。 近年来,一些先进模型如Ollama Gemma3和gpt-oss等在结构化输出领域取得了显著成果。Ollama项目在2024年底首次引入基于预编译图的有限状态机,成功实现了即时约束的结构化输出,为模型输出格式化数据提供了坚实技术基础。
此外,gpt-oss模型虽然基于复杂的思考格式(Harmony)进行生成,但依然能够通过保持正确的输出结构,实现高质量的JSON格式响应。它们的成功说明,通过先进训练和采样策略,模型在无需强约束掩码的情况下,也能部分自我规范输出格式,显示了未来结构化输出发展的潜力。 在面对思考式生成模型时,结构化输出面临新的挑战。这类模型往往包含"思考过程"标记,先进行内部推理,再给出结果输出,输出格式的约束因此更为复杂。实践中有两种主流策略:一种是预填充输出格式,即在生成前注入空白标签如<think></think>,之后限定输出内容范围;另一种是允许模型自由完成思考后再对结果进行强制约束。前者可控性较强但有时破坏模型训练时习惯的输出模式,后者则更贴近真实生成流程,但对约束机制提出更高要求,需要精准定位思考与输出的边界。
结构化输出的未来趋势值得关注。随着模型能力提升及训练任务多样化,模型自身对结构化数据的理解和生成能力将越来越强,或能逐渐减少对外部约束机制的依赖。研究者也在探索如何将结构化输出能力内嵌于模型训练过程中,例如通过指令微调(SFT)强化格式感知。另一重要方向是采样过程的更深度优化,比如在CPU上融合温度调节与softmax计算,利用SIMD指令集更高效地处理大规模概率分布,或用更智能的筛选策略降低重复采样概率。 总的来说,结构化输出是连接大型语言模型与实际应用场景的桥梁。它不仅确保生成数据格式的规范性,提升后续自动处理的准确率,也增强了模型在复杂任务中的可靠性。
当前,结构化输出结合采样机制的技术体系已成形,但仍有大量空间进行创新优化。未来,随着模型本身的进化与采样算法的提升,我们有理由期待更精准、灵活且高效的结构化输出解决方案,从根本上改变人机交互和自然语言理解的格局。随着技术不断成熟,结构化输出无疑将在智能客服、自动编程、文档解析、知识抽取等领域释放更大潜力,为各行各业赋能。 。