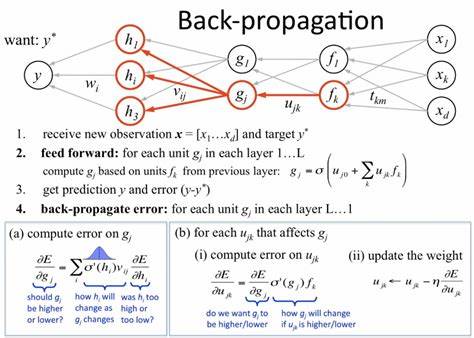
在现代机器学习和深度学习的研究与应用中,线性变换几乎无处不在,诸如矩阵乘法、点积以及Hadamard积等操作构成了神经网络的基础计算过程。虽然正向传播较为直观,但反向传播却因涉及复杂的求导和张量形状变换而常令开发者感到头疼。幸运的是,爱因斯坦求和约定(einsum)为我们提供了一种简洁而强大的表达方式,以及一个巧妙的反向传播技巧,能够极大简化线性变换的求导过程。爱因斯坦求和约定起初来源于物理学中的张量计算,核心思想是自动识别和消除重复的指标,从而通过一个紧凑的字符串表达式实现复杂的张量乘法。将这一理念应用于数值计算库如NumPy和JAX中,可以灵活表示任意线性代数操作,同时保持代码的可读性和效率。举一个经典例子,矩阵乘法可用einsum表达为"ij,jk->ik",对应着两个矩阵A和B依次以索引i,j和j,k表示,结果为矩阵C,其索引为i,k。
通过这一表示,我们不仅能轻松完成正向传播计算,还能基于指标的交换进行反向传播求导。反向传播的核心在于链式法则,需要对损失函数关于输入变量的梯度进行计算,关键是找到合适的变换让梯度形状与参数矩阵对应。爱因斯坦求和约定中,通过简单地调换输入参数的指标,即将正向传播中涉及的矩阵索引"ij,jk->ik"调整为"ik,jk->ij",并用损失梯度替代正向计算的结果,就能快速求得输入矩阵的梯度。具体来说,假设损失函数L对输出矩阵C的梯度为∂L/∂C,那么根据该技巧,仅需执行np.einsum('ik,jk->ij', ∂L/∂C, B)即可计算出∂L/∂A,且该表达式的输出形状与原始矩阵A相符。这种方法极大降低了手动推导和代码编写的复杂度,使得处理任意复杂的einsum表达式的反向传播成为可能。其背后的数学本质是矩阵乘法的梯度可拆分为输入矩阵与权重矩阵转置的乘积,调换索引即等同于对权重矩阵进行转置操作。
为了说明该技巧的有效性,可以结合JAX自动微分库,通过定义正向的线性变换及对应损失函数,调用其梯度计算接口验证手动推导的梯度计算结果。通过比较JAX自动计算的梯度和einsum技巧计算的梯度,二者完全一致,从而证明了技巧的正确性和实用性。除了矩阵乘法,该技巧同样适用于点积、Hadamard积甚至更复杂的线性变换,只要能用einsum表达,则可以用调换索引加上相应的梯度输入实现反向传播。此优势在构建自定义层、优化复杂网络结构时尤为突出,极大提高实现灵活性和代码复用率。掌握这一反向传播技巧,意味着研究者和开发者能够在高维度张量的反向传播上事半功倍,降低出错概率,提升调试效率。而且einsum表达紧凑直观,提升整体代码可维护性和可读性,更易于团队协作。
总之,爱因斯坦求和约定不仅仅是一个数学表达式符号,更是实现高效自动微分的强有力工具。熟练掌握并应用这一技巧,将帮助推动机器学习模型训练的速度和精度提升,同时让代码更简洁优雅。未来,随着深度学习复杂架构的不断出现,依赖高效而灵活的反向传播计算将成为必然。爱因斯坦求和约定的反向传播技巧正是顺应这一需求的利器,为技术人员提供简便而可靠的实践方案。希望这篇内容能在您的深度学习研发道路上带来帮助,助力提升线性变换相关计算的效率和准确度。将这一技巧融入日常编码和算法设计中,相信会给人工智能开发工作注入更多活力和创造力。
。