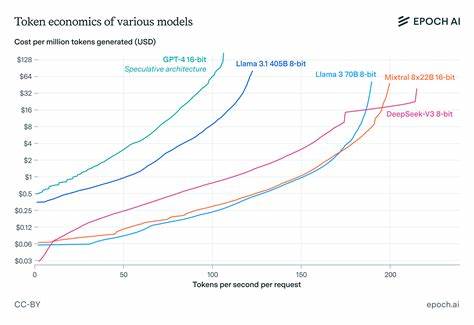
随着人工智能技术的不断进步,尤其是大型语言模型(LLM)在自然语言处理领域的广泛应用,推理速度与成本的平衡成为业界高度关注的话题。语言模型的推理过程不仅涉及复杂的计算,还涉及大量的数据传输和内存操作,这使得推理效率的提升变得尤为关键。近年来,虽然模型技术不断优化,推理的成本已明显下降,但企业和研究机构面临的挑战依然巨大。如何在保证推理速度的同时控制成本,是推动语言模型广泛落地的关键。推理经济学为我们提供了新的视角,从计算资源利用、硬件架构限制以及并行化策略等方面,为理解和优化LLM推理效率指明了方向。 推理过程中的时间消耗主要分为四个部分。
第一是算术运算时间,即GPU执行加法与乘法操作所需的时间,这是实现模型前向推理的核心计算。第二是内存读写时间,主要指从高带宽内存(HBM)中加载数据到计算核心的时长。第三是网络传输时间,源于多GPU环境下数据在网络中发送与接收所花费的时间。最后是固定延迟时间,包括启动内核和GPU集体通信等固有的时延。细致地分析这四个部分,有助于找出影响推理速度的关键瓶颈。 通过对Transformer结构在多GPU并行环境中推理过程的深入研究,发现各部分时间并非简单相加,而是部分时间能够重叠执行。
比如内存读写时间和算术时间之间可能存在并行。合理假设和模型推导使得整体推理时间计算更为准确,为性能优化提供理论依据。在此模型基础上,可以进行参数空间搜索,找到在特定成本限制下的最佳速度配置,或者在特定速度要求下的最低成本实现。换言之,我们可以绘制出推理速度和成本之间的帕累托最优边界,明晰理想的资源分配策略。 值得关注的是网络延迟对推理速度的制约。不少人关注网络带宽限制,认为这是性能瓶颈,但实际情况更复杂。
在快速推理场景中,网络传输的数据包通常较小,带宽限制鲜少占主导地位,反而是网络延迟成为瓶颈。即使具备极高网络带宽,在多GPU进行推理时,因每次通信启动的固定延迟导致整体效率受限。这一发现深刻解释了为什么增加GPU并行度时推理速度提升不如理论无限制扩展那么显著。网络延迟成为真正的“速度天花板”,影响着实际部署和扩展策略。 在推理速度与模型规模的关系上,研究表明,密集型Transformer模型生成单个token的速度大致随着模型参数数量的平方根的倒数变化。换句话说,随着模型参数数量的增加,推理速度呈现非线性下降趋势。
同时,所使用GPU的内存带宽对推理速度也有重要影响,速度约随着内存带宽的三次方根增加。这些规模定律不仅能从理论推导中得到支持,同样经过实证验证,成为评估和设计推理系统的重要参考。 对于并行策略,有数据并行与流水线并行是两种主要手段,但其应用效益有显著区别。数据并行通过多个GPU协同处理不同的数据批次,适合加速推理过程且通信需求相对较小。相比之下,流水线并行需要将模型切分成多阶段,各GPU承担不同计算阶段,虽能支持更大模型的内存需求,但带来的通信开销和流水线空闲时间使效率下降。除非内存容量成为限制因素,否则数据并行方案通常更优。
在现代高带宽GPU如H100上,流水线并行的优势仅在非常低的解码速度下才可能显现。 推理时的内存带宽和网络延迟瓶颈,也为投机性解码技术的采用创造了契机。投机性解码通过在单次前向计算中生成多个token,减少每个token所需的启动及通信延迟,有效将延迟成本摊薄,带来推理速度最高可达两倍的提升。该技术虽然并不能降低算术运算和带宽消耗,但在快速推理场景中,这些并不是主要瓶颈。投机性解码已被实践证明不仅能提升速度,还不引入额外成本或性能下降。 推理经济学研究的意义在于,它揭示了AI推理系统中的隐形成本与性能壁垒,打破了以往“推理速度线性提高,成本无上限上涨”的误解。
实际上,受限于硬件物理特性和网络结构,推理速度提升远比预想中更具复杂性和挑战性。理解这些基础规律,能帮助企业科学地规划资源投入,避免盲目扩容,找到最经济的推理解决方案。同时,也为未来硬件设计和系统架构创新指明优化方向,比如降低网络延迟、提升GPU内存带宽和改善并行策略等。 近年来AI推理市场需求与日俱增,OpenAI、Anthropic等主要AI企业推理收入实现三倍以上年增长。虽然模型体积趋向紧凑和价格下降,但推理性能提升的边际效益仍值得深究。通过更好地理解推理经济学,行业可以制定更加有效的商业策略和技术路线,加快AI应用普及的速度,推动技术从实验室走向更广泛的实际应用场景。
总之,语言模型推理经济学不仅是一门理论学问,更是一项关乎AI产业可持续发展的重要研究。它帮助我们认清当前AI推理的瓶颈与潜力,通过优化硬件利用、并行策略和推理算法,提高推理速度,降低成本,最终实现更快更经济的智能系统,为未来智能化社会奠定坚实基础。随着推理需求持续增长,深入研究和应用推理经济学将在提升AI整体能力与实用价值方面发挥举足轻重的作用,值得学术界和工业界持续关注和投入。