随着人工智能技术的飞速发展,越来越多的行业开始依赖大型语言模型(LLMs)来提升业务效率和决策质量。金融领域作为数据密集且高度依赖精准分析的行业,对智能系统的准确性和透明度提出了极高的要求。在此背景下,Kensho推出了S&P AI Benchmarks,一套专门针对金融与商业应用场景设计的AI评测基准,旨在推动AI系统,尤其是大型语言模型,在复杂且专业的金融问题上实现可信赖的表现。S&P AI Benchmarks基于标普全球(S&P Global)丰富的数据资源和行业经验,涵盖了两个主要的评测集,分别聚焦于金融基础知识和长文档问答(Long-Document QA)。这两个评测集的设计理念都紧扣真实世界的业务需求,确保被测试模型不仅具备广泛的知识储备,更能展现出扎实的量化推理和信息理解能力。金融基础知识评测关注模型对核心金融概念、市场机制和经济指标的理解,旨在检验其处理金融业务中典型知识点的准确度。
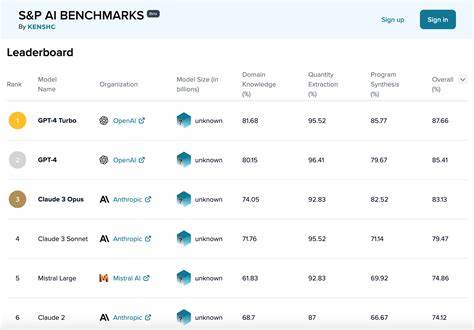
与之相比,长文档问答则更加考验模型在处理大量结构化和非结构化文本数据时的推理能力。金融报告、产业分析乃至复杂财务文档都需要模型能有效把握关键信息,作出有依据的回答。参与者无需受限于特定机构背景,无论是学术界的研究团队、大型企业还是独立模型开发者,都能自由报名加入该评测计划。公开的排行榜不仅为不同模型的性能提供了透明展示,也激发了多方在技术研发上的创新和协作。此外,排行榜以百分比形式直观体现模型在各项任务中的表现,方便比对优劣和发现改进空间。从当前的排名来看,OpenAI的o1模型在金融基础知识领域表现优异,达到了92.1%的总分,紧随其后的是Deepseek和Anthropic的型号。
长文档问答领域则由Claude 3.7 Sonnet与Needl共同领跑,其精准度均达到55.11%,这显示出长文本推理依然是AI模型挑战较大的环节。S&P AI Benchmarks的诞生,背后反映出金融行业对AI系统提出的特殊需求。尽管现代大型语言模型已在多模态问答和代码生成等任务中成绩斐然,但数量化推理及准确处理数字相关信息却始终难以攻克。这直接影响了模型在实际金融分析、风险管理及财务决策中的应用可靠性。先前的行业评测多半集中在情感分析、文本分类或命名实体识别,虽有价值但难以全面反映模型面对复杂金融场景的能力。作为回应,Kensho与S&P Global紧密合作引入了更具挑战性和代表性的测评设计,旨在形成一套客观且具权威性的评价体系。
通过模拟真实的商业环境和金融逻辑,测试数据涵盖数量推理、语义解析与多步骤问题解决,确保模型不仅“知道答案”,更能“算出答案”。公开透明的评测流程及多维度的性能指标,有助于营造公平竞争环境。这也方便了模型开发者根据反馈精准定位弱点,推动模型在准确率、稳健性和适用性上的全面提升。值得一提的是,S&P AI Benchmarks不仅是一种技术检测工具,其背后还蕴含着推动金融行业AI安全与合规的理念。透明和标准化的评价体系能够加强各利益相关方对AI结果的信任,是实际应用落地的关键一步。未来,在法规不断演进和市场需求日益多样的推动下,基于该基准打造的模型将更具行业特性,更具解释性和灵活性,从而为金融机构带来更深远的价值。
伴随着持续投入与技术迭代,S&P AI Benchmarks有望成为金融智能化转型的重要推动力量。它不仅促进了跨界合作与学术交流,也为广大AI开发者提供了展示实力和获取反馈的国际化舞台。对于希望通过人工智能革新金融业务的企业而言,关注并积极参与这一评测体系,是掌握行业前沿、优化技术路线的必由之路。综上所述,S&P AI Benchmarks以其严谨科学的评测内容和开放包容的参与机制,为金融与商业领域的人工智能应用树立了新的标杆。它不仅令大型语言模型的能力评估更准确,也推动了AI技术与金融专业知识的深度融合。随着基准体系的不断演进及社区力量的壮大,我们有理由期待未来金融智能应用将更加智能、高效和可靠,为整个行业创造更广阔的发展空间。
。