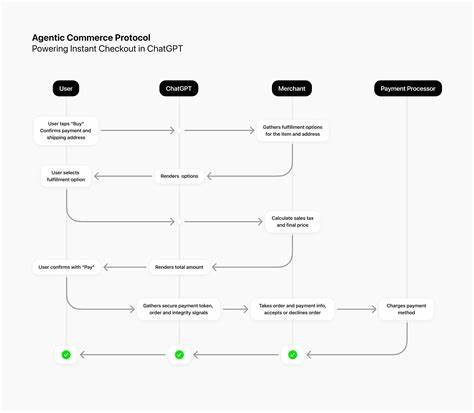
在大模型时代,理解强化学习如何用于微调语言模型变得愈发重要。对于习惯于计算机视觉领域的研究者来说,术语和细节可能显得陌生,但核心思想并不复杂。本文从直观和工程角度拆解 PPO(Proximal Policy Optimization)与 GRPO(Group Relative Policy Optimization)在 RLHF(从人类反馈的强化学习)流程中的作用,说明两者在性能、算力与实现复杂度上的差异,并讨论 DeepSeek R1 报告中那种"残酷的简洁性"为什么会奏效。文章旨在提供可操作的理解,帮助你决定何时使用哪种方法,以及如何在工程上权衡资源与稳定性。 首先回顾一下 RLHF 的整体流程。通常会先用人工标注的数据训练一个奖励模型,该模型学习预测在给定提示下不同候选回答的好坏。
随后使用强化学习方法微调基础语言模型,使其生成的文本在奖励模型上的分数更高。整个流程把一个生成模型视为策略,把生成的词作为动作,把完整回答的奖励作为策略优化的目标。奖励模型、策略(即语言模型)以及在某些方法中额外引入的价值函数(critic)是关键构件。 PPO 是当前产业界最常用的策略优化方法之一。它的核心在于稳定更新:通过计算旧策略与新策略对每一步动作概率的比值,并对这个比值施以裁剪(clipping),来避免一次更新导致策略出现过大的漂移。PPO 的优化目标由四部分构成:裁剪后的替代损失用于最大化优势(advantage);熵项鼓励探索;KL 惩罚项抑制策略偏离参考策略;价值函数的均方误差用以训练 critic,使其能够对部分生成的文本估计最终奖励。
优势的估计通常依赖于通用优势估计(GAE)。优势定义为某一步动作带来的长期回报与在该状态下平均回报的差值。PPO 中为了兼顾偏差与方差,常用多步时序差分(TD)混合的方法。价值函数的存在其实就是为了给出对未完成序列的奖励预测,因为奖励模型只在完整序列上给出非零分数。于是训练一个 critic 去预测奖励成为必要,以便能在 token 层面进行梯度更新并计算 GAE。训练过程因此呈现 actor-critic 的形式:策略和价值函数同时更新,而价值函数需要与当前策略保持同步。
从工程角度看,PPO 的优点是稳定和成熟。价值函数提供了一种低方差的基线,使得训练更为高效。然而,这个好处也带来了明显的成本。要训练一个和策略规模相当的 critic,会消耗大量内存与计算资源;在 RLHF 的场景中,策略往往是大型语言模型,维持一个同等规模的 critic 意味着训练成本几乎翻倍。此外,价值函数也可能引入额外的不稳定来源:如果 critic 的预测滞后或偏差较大,会误导策略更新,导致训练震荡或崩溃。 GRPO 的设计初衷旨在绕过价值函数带来的复杂性与成本。
核心思想相当简单且优雅:对每个提示采样一组多个完整回答,用奖励模型对每个回答打分,然后在组内对分值进行归一化,得到组内优势估计。具体来说,把每个回答的奖励减去同组的平均奖励,再除以同组的标准差,作为该回答的相对优势。将这个优势直接用于策略优化,配合与 PPO 类似的裁剪损失和 KL 惩罚项,但不需要 critic 与 GAE 的复杂估计。 从统计角度理解 GRPO,可以把它视为对蒙特卡洛方法的一种放大:通过在相同提示下生成大量样本,直接用样本内的基线(batch baseline)来降低方差。历史上,在 REINFORCE 类算法中使用样本平均作为 baseline 并非新颖,但 GRPO 将这个思想放大到成百上千个样本,这依赖于现代硬件的并行采样能力。组内归一化把奖励的量纲标准化,使得不同提示之间的奖励可比,同时抑制了极端奖励对更新的影响。
GRPO 的工程优势显而易见。首先,它根本不需要训练和维护一个 critic,从而节省了大量显存和计算资源,模型的内存占用可接近减少一半。其次,实施复杂度低:不必设计价值函数架构、选择合适的更新频率或处理 value-prediction 的过拟合与偏差。第三,基于组采样的探索天然鼓励多样性,因此在许多实现中可以省略熵项,而只保留裁剪损失和 KL 惩罚。 但是 GRPO 也并非没有缺点与限制。它对并行采样和批量大小有较强依赖:要获得低方差的组内基线,需要为每个提示采样很多回答,这意味着在带宽、采样时间以及并行推理能力上要有充足的资源。
对于延迟敏感或资源受限的场景,GRPO 可能不划算。另一方面,组内标准化在奖励分布非常偏斜或包含异常值时可能不稳定,因此对奖励函数的设计与鲁棒性要求更高。再者,GRPO 使用的基线是组内样本的统计量,而非一个基于状态的长期回报估计,在某些需要细粒度 token 层次奖励分配的任务上,缺乏 critic 可能导致样本利用效率不如基于价值函数的方法。 在实践中,如何选择 PPO 或 GRPO 要看资源、任务特性与工程预算。如果你的集群支持极高效的并行采样,且希望尽量减少训练堆栈中的可学习模块与工程复杂性,GRPO 是一个极具吸引力的选择,尤其当奖励可以在完整回答上快速评估时。如果训练成本与显存是第一优先级,同时对训练稳定性与样本效率有高要求,PPO 仍然是稳妥之选,尽管它在实现和调参上更繁琐。
DeepSeek R1 的经验是一面非常值得思考的镜子。报告中的核心是"残酷的简洁性":通过放弃复杂的奖励模型、减少人工监督、并用超大规模采样与规则化的判定替代学习型组件,R1 实现了在推理与训练流程上的大幅简化。具体到奖励信号上,他们大规模采用基于规则的确定性检查,比如答案正确性、格式一致性、语言一致性等,避免了昂贵且不稳定的神经奖励模型。这样的做法减少了奖励被模型"黑箱利用"的风险,同时极大压缩了数据标注与训练成本。 R1 选择直接对基础模型施行 RL 而跳过传统的监督微调(SFT),并结合 GRPO 式的海量采样和组内筛选,表明在优秀的预训练模型基础上,RL 可以作为一种自我进化的机制。工程上,他们还使用了拒绝采样策略和事后筛选:在训练结束后生成数十万条推理轨迹,仅保留正确或满足规则的样本用于后续监督训练或蒸馏,这种"生成-筛选-蒸馏"的流水线既简单又高效。
从研究与实践的角度来看,几个实现建议值得关注。首先,奖励的定义至关重要。无论采用神经奖励模型还是规则化奖励,必须考虑对抗性脆弱性:如果奖励可被模型通过简单手段操纵,优化过程会偏离人类期望。规则化、断言式检查或多模态奖励能够在一定程度上缓解此类问题。其次,KL 惩罚或类似的保守更新策略不应被忽略:在对大型语言模型进行 RL 微调时,维持与原始模型的相对接近可以避免生成质量的退化和不必要的偏差。再次,监控与安全机制要早期部署:在线评估、自动化异常检测和人工抽查能帮助发现奖励劫持或退化趋势。
从调参角度,PPO 的关键超参数包括裁剪范围 epsilon、GAE 的 lambda、价值函数更新速率以及 KL 权重。GRPO 的关键在于每个提示的采样数、组内归一化策略以及是否加入熵项或其他正则项。无论采用何种方法,都需要在小规模试验上先行调研,再逐步放大训练规模以观察系统行为。 最后,关于未来的研究方向,有几条尤其值得关注。如何在减少 critic 的前提下提高样本利用效率,是一个重要问题。混合方法可能会带来收益,比如在多数提示上使用组基线,在少数需要细粒度解释或稀疏奖励的提示上引入轻量级的价值估计器。
另一个方向是更鲁棒的奖励设计,结合规则化判定、学习型奖励与对抗性检测,以提升 RLHF 的安全性与可靠性。还有一个实用方向是优化大规模并行采样的系统架构,降低每个提示生成大量回答的延迟与成本,从而让 GRPO 更易于工程化推广。 总的来说,从视觉研究者的角度看,PPO 与 GRPO 代表了两类不同的工程与理论权衡。PPO 更侧重于样本效率与理论稳健性,代价是更高的实现复杂度与资源消耗。GRPO 则以直观与工程简洁性取胜,通过海量并行采样和组内归一化替代价值函数,显著降低系统复杂度与算力需求,但对并行推理能力和奖励设计提出更高要求。借鉴 DeepSeek R1 的经验,简化并结合规则化思想,在许多实际场景中能够以较低的工程成本取得令人惊讶的效果。
对于希望在 RLHF 中快速实验的视觉研究团队,建议先在有限计算预算下尝试 GRPO 的思路,配合严格的规则化评估;在对样本效率与稳定性有更高要求时,再考虑引入 PPO 与 critic。理解每种方法背后的统计直觉与工程限制,才是把 RLHF 工具箱真正用起来的关键。 参考与延伸阅读可以从 PPO 的原始论文、GAE 相关工作、以及最近 DeepSeek R1 的技术报告入手,同时关注社区对组采样策略、奖励鲁棒性与大规模采样系统优化的讨论。通过理论理解与小规模实验结合,你将能更快地把这些强化学习方法应用到语言模型微调与跨模态研究中。 。