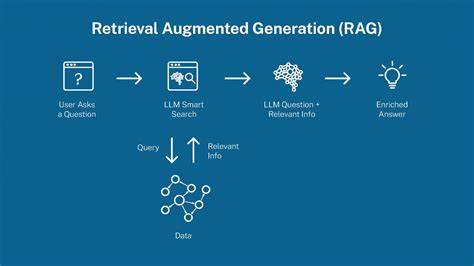
随着人工智能技术的迅速发展,大规模语言模型(LLMs)以其强大的文本生成和推理能力,正在深刻改变自然语言处理领域。然而,尽管这些模型在语义理解和语言生产上表现出色,其在实际应用过程中仍面临众多挑战,如幻觉生成、知识时效性不足以及领域专业性局限等问题。检索与结构化增强生成(Retrieval And Structuring Augmented Generation,简称RAS)作为一种创新方法,通过动态的信息检索与知识结构化手段,有效提升了语言模型的实际表现和应用价值。RAS技术的核心理念是结合外部知识库的动态检索能力与结构化知识的组织优势,增强模型对上下文信息的获取能力,从而减少错误信息生成,提高内容的准确性和专业度。检索层面,RAS广泛应用多种技术手段,包括稀疏检索、稠密检索及混合检索方法。稀疏检索往往利用传统的关键词匹配算法,依靠文档中词汇的显著性和频率寻找相关信息,适合处理大量文本且计算开销较低。
相较之下,稠密检索利用深度学习构建文本的向量表示,通过语义相似度计算实现更精准的匹配,尤其在含糊和多义表达情况下表现优异。混合检索则融合两者优势,兼顾效率与效果,为知识获取提供多样化路径。文本结构化是RAS方法的另一关键环节。通过构建分类体系、层级归纳以及关键信息提取等手段,非结构化的文本数据被转换为含义明确、条理清晰的知识表示形式。此类结构化过程不仅简化了信息的后续处理,还为大语言模型提供了更加准确且易于理解的知识载体。具体技术如构建领域词汇树、推断类别标签以及从原始文本中抽取实体与关系等,都极大丰富了模型的知识表达能力。
在与大规模语言模型的整合层面,RAS通过提示设计、推理框架和知识嵌入技术,实现了知识与语言表达的深度融合。提示工程利用结构化知识设计有效输入,让模型更好地理解上下文并生成高质量文本。推理框架则支持多步逻辑推导和复杂任务的分阶段处理,提高了模型推理的准确性和可靠性。同时,知识嵌入技术将提取的结构化信息直接嵌入到模型内部权重或表示空间,增强模型对专业领域知识的掌握。尽管RAS在提升LLMs能力方面展现出巨大潜力,当前技术仍面临诸多挑战。检索效率问题因大规模数据访问和实时反馈需求而日益突出,优化索引结构和加速搜索算法成为关键。
结构质量方面,如何保证自动生成的知识结构合理、无歧义且覆盖面广,是提高系统整体性能的重要因素。知识融合过程中,确保外部信息与模型内在知识的无缝衔接,防止信息冲突和理解偏差同样是技术难点之一。未来,RAS领域的研究和应用正朝着多模态检索和跨语言结构化方向迈进。多模态技术融合文本、图像及音频信息,将极大拓展模型感知范围和应用场景,推动智能问答、内容生成等任务的跨界创新。同时,跨语言结构化研究促进不同语言和文化背景知识的普适表达与利用,助力全球信息交流和智能服务的多样化发展。此外,交互式系统的设计将使RAS技术更具用户定制化和实时响应能力,推动智能助手和决策支持系统在复杂场景中的广泛应用。
总体而言,检索与结构化增强生成方法为解决大规模语言模型在实际应用中遇到的知识更新滞后、信息准确度不足等问题提供了有力支撑。它不仅丰富了模型的知识来源,也优化了信息处理流程,使生成内容更具权威性和针对性。随着技术的不断完善与创新,RAS有望在人工智能的智能问答、内容创作、专业咨询等多领域发挥更大影响力,成为推动自然语言处理迈向更高水平的关键驱动力。对研究者和从业者而言,深入理解RAS的原理、技术挑战以及应用潜力,不仅有助于把握当前人工智能发展的前沿趋势,更为构建更智能、更可信的语言理解和生成系统奠定坚实基础。未来,结合多模态数据和跨文化多语言环境,推动RAS技术的应用创新,将引领人工智能向更广泛的社会需求和复杂应用场景迈进,开启语言智能的新篇章。 。









