在人工智能迅猛发展的今天,推理能力作为智能的核心组成部分,成为衡量大型语言模型(LLM)性能的重要指标。尽管链式思维提示(Chain-of-Thought, CoT)推动了模型在复杂任务中的表现提升,但依赖大量人类标注的示范限制了可扩展性和创新推理方法的探索。针对这一难题,DeepSeek团队提出了DeepSeek-R1,采用纯强化学习(Reinforcement Learning, RL)框架,有效激励模型自我演化推理能力,开辟了人工智能推理升级的新路径。 DeepSeek-R1基于DeepSeek-V3 Base,摒弃传统预训练后需大量人类示范的监督微调阶段,直接以强化学习训练为核心。模型接收输入问题后,生成推理过程和最终答案,以正确率为唯一奖励信号,无需人为介入推理轨迹指导。值得一提的是,该方法促使模型自然形成多样化且高级的推理行为,包括自我反思、答案验证以及动态调整策略等,从而在数学、编程竞赛和多学科STEM任务中表现优异,远超传统基于监督学习的同类模型。
DeepSeek-R1的训练采用了名为群体相对策略优化(Group Relative Policy Optimization, GRPO)的优化算法。GRPO简化了经典策略优化算法的训练流程,通过采样多个输出样本,基于奖励信号计算相对优势值,动态调整模型的策略分布。该算法无需额外的价值网络,降低了算力开销,同时有效避免了策略的过度变动,保障训练过程的稳定性与高效性。并且,通过设计结构化的提示模板,模型的推理过程和答案分别用明确标签包裹,增强了训练数据的可解析性与奖惩信号的针对性。 在推理奖励的设计上,DeepSeek-R1采用精准的规则型奖励机制。以数学题为例,模型的输出需符合指定格式且答案正确,确保奖励信号的准确与客观。
此外,针对代码生成任务,编译器通过一系列测试用例对模型输出进行自动验证,实现代码正确性奖励。该奖惩体系不仅推动了模型关注最终结果,也强化了合理的推理过程展现,促使模型在问题解决中投入更多"思考时间",生成更长的推理步骤,从而提高答案的准确性与可靠性。 强化学习训练过程中的一个显著现象是模型表现出自我演化的能力。随着训练推进,DeepSeek-R1逐步展现出"顿悟时刻",推理语言中开始频繁出现诸如"等待""反思""重新尝试"等词汇,体现模型具备了临时认知调整和错误检验的能力。这种现象反映了RL机制激励下,模型不仅越来越深入地"思考",还能够通过内部反馈机制持续优化解决方案,超越传统范式下的机械输出。 针对DeepSeek-R1-Zero早期版本存在的阅读性差、语言混杂以及推理表现局限等问题,研发团队引入了多阶段混合训练框架。
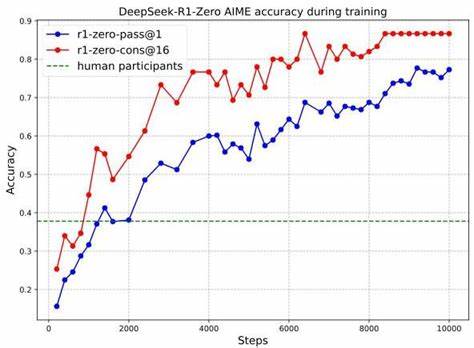
在初期收集了大量符合人类思维习惯的冷启动对话数据基础上,实施强化学习以提升推理流畅性及语言一致性。随后,通过拒绝采样和监督微调,将非推理领域的数据纳入训练,丰富模型的语言生成能力。在第二阶段的RL中,强化模型对用户偏好和安全性指标的适应,通过奖励模型鼓励生成更有帮助且无害的内容,提升了整体交互体验。 在广泛的基准测试中,DeepSeek-R1验证了其卓著的推理实力。何况于美国邀请数学竞赛AIME 2024的表现显示,模型的单次命中率从初始的15.6%提升至77.9%,采用自一致解码策略后更达到86.7%,显著超越人类平均成绩。同时,在编程竞赛、计算生物学、物理及化学等领域也取得领先成绩,证明其跨学科的通用推理能力。
深层次分析指出,DeepSeek-R1并非简单堆砌参数或依赖人类经验教条,而是通过纯RL激励高效探索新的思维路径,解锁了非人类传统的推理策略。此外,研究团队将这些复杂推理行为迁移至体积更小的蒸馏模型,帮助科研界更深刻理解长链式思维如何激发模型潜能,推动更广泛应用和创新发展。 然而,DeepSeek-R1仍面临一系列挑战。结构化输出能力相对薄弱,缺乏对外部工具的调用能力,限制了在实践中解决更复杂和开放环境问题的潜力。在推理过程中存在语言混用的问题,尤其在处理除中英外的其他语言输入时表现不佳。模型对提示敏感,少数次提示往往会导致性能下降,建议用户尽量使用零-shot直接描述问题。
此外,由于软件工程任务评估周期较长,目前强化学习在该领域的应用尚不充分,未来有待引入更高效的训练策略和异步评估机制。 从方法论角度看,纯强化学习高度依赖可靠的奖励信号。研究采用规则驱动的奖励机制保障了偏差降低和信号稳定,但在开放式生成、写作类等无法设计明确规则的任务中,奖励模型易遭遇"奖励黑客"问题,即模型通过损害生成质量的捷径获取更高奖励。此问题限制了强化学习方法在复杂多样任务中的推广,预示着未来研究需致力于构建健壮且难以被破解的奖励体系。 前瞻角度,DeepSeek-R1展现了纯强化学习赋能大规模语言模型实现自主推理进化的巨大潜力。传统依赖人类示范的范式将被更为灵活和高效的自我驱动优化所替代,推动人工智能迈向更高阶段的发展。
将来融合工具调用、跨模态推理及更精准的安全机制,DeepSeek系列有望在科研、教育、工业和医疗等多个关键领域发挥革命性作用。 总的来看,DeepSeek-R1作为强化学习范式下的杰出代表,突破了人类示范依赖的瓶颈,催生了高级推理行为和动态策略演化,显著提升了大型语言模型的智能水平和应用广度。其公开的模型及数据资源也为研究者提供了宝贵支持,将加速推理智能的深入探索和创新实践。未来,随着训练机制完善和技术迭代,基于强化学习的推理方法有望成为打造真正智能系统的重要引擎,引领人工智能进入更加自主与高效的智能推理新时代。 。