随着人工智能技术的快速发展,大型语言模型(LLMs)在科学研究中的应用日益广泛,尤其在化学领域引发了广泛关注。大型语言模型通过海量文本训练展现出强大的语言理解和生成能力,甚至在医学和法律等专业领域达到了接近专家水平的表现。与此同时,化学作为一门高度专业且以知识密集和复杂推理著称的自然科学,成为评估这些模型能力边界的绝佳试金石。本文将围绕大型语言模型与化学专家在化学知识和推理能力上的表现进行深入对比,剖析模型的优势、短板与未来发展方向。 大型语言模型化学能力的突破源自其对大量化学文本资源的学习,包括教科书、科研论文和专业数据库。这使其能够掌握基础的化学术语、反应机制和物质性质等知识点。
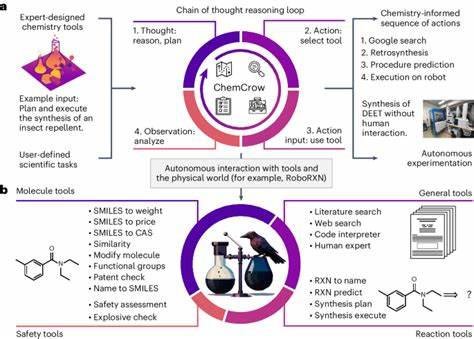
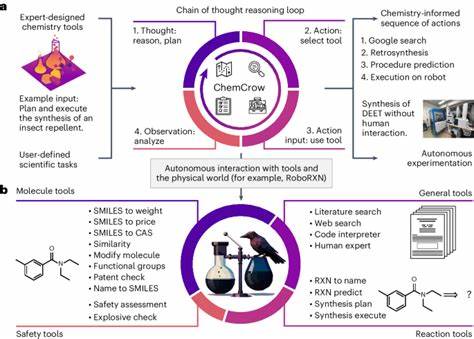
此外,部分前沿模型结合了工具增强功能,例如联网搜索和自动合成规划,进一步扩大了其实际应用能力。多个研究验证了这一点,某些模型在经过针对化学数据调整后,能够在化学考试中取得超越普通化学专业人员的成绩,甚至在特定任务上表现优异。 不过,模型的表现虽然引人注目,但也存在显著不足。首先,尽管模型能够记忆大量显性知识,却在部分基础性知识题目中出现错误,这表明其内存式学习尚不能完全替代化学家长期积累的隐性知识和经验。其次,这些模型在处理复杂的化学推理和结构解析时存在困难,比如核磁共振谱信号数量的准确预测就表现欠佳。其原因之一是模型对分子结构的理解主要依赖于SMILES等线性表示,而缺乏对分子三维空间构象和对称性的深度推理能力。
此外,模型通常无法有效判断自身预测的置信度,出现过度自信的错误信息输出,给依赖自动化辅助的科研流程带来潜在风险。 与此形成鲜明对比的是,化学专家凭借系统的专业训练和实践经验,能对复杂问题做出准确判断,特别是在需要跨领域知识整合和实验设计创新时展现出卓越能力。专家还能灵活应用工具和数据库进行动态查询,比单靠文本记忆和推理更具弹性。然而,专家在处理信息量巨大且不断更新的化学文献时显得力不从心,模型却可快速消化大量书面资料,展现出在知识存储与即时访问路径上的独特优势。 鉴于此,科研团队开发了ChemBench这样兼顾知识和推理的评估框架,收录超过两千七百道涵盖化学广泛领域的问题,涵盖基础知识、复杂推理、计算、化学直觉等不同技能维度,并邀请专业化学家参与对比评测。结果显示,现有顶尖大型语言模型在整体表现上超过了专家的平均水平,甚至在部分子领域接近或优于最佳人类参与者。
此事实引发了化学教学、科研方法乃至专业考试设计的重新思考:人类化学教育可能需更多聚焦于理解与批判性思维而非单纯记忆。 进一步分析表明,不同模型在不同化学子领域的表现差异显著。通用化学与技术化学领域得分相对较高,而安全性和分析化学等领域依旧表现脆弱。此外,模型对于基于文本数据的典型教科书题目表现优异,但面对更加需要原创性推理或结构感知的问题时,表现明显下降。此种差异也暗示了训练数据的广度与深度对模型通用性的限制。 对比研究还发现,模型的规模与化学任务表现存在正相关关系,暗示未来通过大模型扩展和更专业数据集的结合,有望进一步提升性能。
此外,模型尚未能有效模拟化学家的“化学偏好”,即在药物发现等领域通过直觉判断化合物优劣的能力。该缺陷目前制约了模型在新药筛选和分子设计中的应用潜力,表明未来需要引入偏好学习等先进训练策略,实现人机协同优化。 一个不可忽视的问题是大型语言模型安全与伦理风险。在化学领域,强大的设计和预测能力可能被滥用用于危害公共安全的用途,例如设计有害化学物质。由于模型对安全相关知识的自我限制不够严格,且部分普通用户缺乏专业判断,错误或误导性回答可能带来严重后果。因此,建立更完善的安全机制、明确的使用规范和对输出的可信度评估机制,是未来推广应用的关键要素。
尽管存在局限,当前研究表明,在辅助化学研究和教学中,大型语言模型展现出巨大的潜力。有朝一日,这些模型将具备跨越语义理解、知识检索、实验设计与数据分析的综合能力,成为化学家的得力助手。未来的化学教育可能需要整合人工智能训练,使学生不仅学会传统理论,更懂得如何与智能系统协作,依赖批判性思维甄别并提升自动化建议的质量。 要充分实现上述愿景,科学界亟需完善化学语言模型的训练与评估体系,提升其对结构信息的深度理解能力,扩大专业数据库的接入权限,并研发更加精准的自信度预测方法。同时,开放透明的测试平台和专家社区参与机制应成为推动模型持续进步的基石。只有在模型性能、可用性、安全性得到平衡的前提下,大型语言模型才能真正转化为推动化学科学发展的革命性工具。
综上所述,虽然大型语言模型在化学领域已展现超越多数人类专家的知识掌握与问答能力,但在深层次推理、化学直觉、安全判断等核心环节仍与专业化学家存在差距。未来的挑战在于融合人类智慧与机器智能的优势,推动更为智能、可靠且多面向的化学研究工具发展。这一进程不仅将重新定义科学家的角色,也必将引领化学教育和科研进入崭新的智能时代。