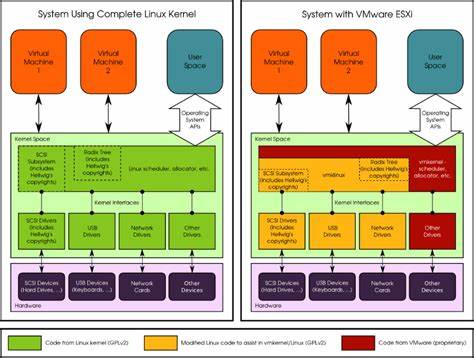
Linux内核作为开源操作系统的核心,长期以来以其强大的性能和灵活的适配性赢得全球开发者与厂商的青睐。开源许可证GPL的设立,确保了用户可以自由获取修改后的源代码,维护了软件生态的透明和公平。然而,现实中部分设备制造商未能遵守GPL协议,私自封闭内核源码,导致用户无法获得修改版本的代码,侵犯了其正当权利。面对这样的状况,反编译技术成为了解决方案之一,尤其是字节级等价反编译 - - 即通过解析设备中的内核二进制文件,重构出精确匹配原始代码的C语言版本。本文聚焦基于进化算法的字节级反编译方法,探讨其原理、挑战及未来潜力。反编译作为从机器码还原高级语言程序的技术,传统方法大多以语义等价为目标,难点在于复杂程序逻辑的精确还原及语义验证的不可判定性。
与此不同,字节级等价反编译追求生成一段在编译后能够产生与目标二进制完全相同字节序列的源代码,从而保证严格一致的运行结果和执行路径。实现这一目标的方法必须克服极高的搜索空间复杂度及编译器和优化参数的不可知因素,因此需要采用智能优化策略。进化算法作为模拟自然选择和生物进化过程的群体智能优化方法,具备在复杂、非线性、多峰值空间中寻找最优解的独特优势。其核心思想在于通过选择、交叉、变异等操作,基于适应度函数不断演化候选解群体,逐步逼近问题的最优或近似最优解。针对字节级反编译,将源代码抽象语法树(AST)作为进化算法的基因表现形式,利用编译后生成的机器码与目标二进制字节的差异作为适应度评价,可以引导算法优化源代码结构和语句组合。初始种群的构建是关键环节,随机生成程序片段效率较低且易陷入局部最优。
结合现有传统反编译工具生成的半成品代码或利用机器学习模型输出的草案作为起点,能显著提升搜索效率和最终质量。此外,减少源代码语言特征的自由度,比如限制循环结构类型或排除复杂数据结构的使用,可以有效控制搜索空间的规模,降低计算难度。进化算法在内核代码反编译领域应用尚属探索阶段。过去相关研究多集中于小型程序的实验验证,证明通过进化策略实现字节级一致性有一定可行性,但规模和复杂度均难以应对完整的Linux内核模块。Linux内核庞大且包含多样化功能模块,加之编译环境参数差异带来的生成代码差异,都对反编译准确性提出了极高要求。内核二进制文件从设备提取后,首先需要准确识别和定位代码区域,剥离非代码数据以减轻反编译负担。
结合底层的汇编反汇编技术,或者提取编译中间表示(IR),可以为进化算法提供更底层、更接近源代码语义的分析基础。尽管如此,保证进化算法搜索结果不仅功能一致,还能保持良好可读性和维护性,是另一个巨大的挑战。反编译得到的源代码往往非常晦涩难懂,命名混乱,结构不合理。为此,后续的代码优化、重命名和格式化是提升代码质量的必要步骤。近年来,借助大型语言模型(LLM)辅助代码理解和重构的研究兴起,为提升反编译代码的人类可读性打开了新途径。除了学术研究意义,此类技术的发展对维护开源生态和监督GPL许可的执行具有实际价值。
比如针对一些电子书阅读器、嵌入式设备等采用未开源内核的产品,用户面临缺乏官方源代码更新、安全修复闭塞等问题。通过字节级反编译恢复内核代码,有望推动设备支持主线内核,促进社区共同开发和维护。不过,反编译技术也涉及法律和伦理层面的复杂考量。如何平衡知识产权保护与用户合法权益,确保反编译活动符合当地法规,是该领域必须谨慎对待的问题。总体而言,利用进化算法解决字节级等价反编译难题,仍处于早期探索阶段,但其结合优化技术、人工智能辅助分析以及对特定设备目标的定制化策略,展现了强大潜力。面对日益复杂的软件环境和对开源透明度的诉求,推动该领域深入研究,有助于提升软件安全、促进开源授权的公平执行,并推动技术创新与产业生态的协调发展。
随着算法效率提升、硬件性能增强和机器学习技术融合,未来字节级反编译有望实现对复杂内核模块的高效还原,实现理论突破走向实际应用。进化算法的弹性和群体智能优势,为挑战极高维度和非凸优化问题提供了有效工具。结合具体场景,如针对特定硬件平台或编译器环境开发定制化适应度函数和遗传操作,有助于进一步提高反编译质量。正如任何前沿技术一样,字节级等价反编译的研究路径可能充满未知和挑战,但同时代表了开启闭源软件黑盒、捍卫用户权利和推动开源理念的关键一步。未来探索无疑需要跨学科合作,涵盖操作系统、编译原理、人工智能与法律伦理等多个领域,共同推动科学技术向更加公平开放的方向发展。综上所述,基于进化算法的Linux内核字节级反编译,既是技术上的极限挑战,也是开源生态正义的重要体现。
通过不断试验和优化,有望最终实现高可信度的二进制程序源代码还原,解决GPL协议违背带来的实际问题,促进技术创新与开源精神的融合。 。