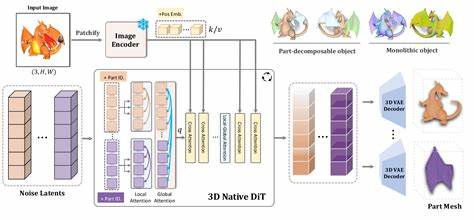
随着计算机视觉和三维建模技术的不断发展,如何高效且精确地从二维图像中生成三维物体模型成为了研究热点。传统方法通常依赖于单一整体的3D模型生成,或者采取分阶段处理,即先进行图像分割再重建每一个部分。面对复杂场景和多对象结构,这些方法受限于流程繁复且难以保证生成结果的结构完整性。为了解决这些难题,来自Yuchen Lin等人的团队提出了创新型结构化3D网格生成模型——PartCrafter。这一方法通过组合潜在扩散变换器,实现了端到端的多部件3D生成,且无需依赖预先的图像分割,极大提升了3D网格生成的效率与细节表达能力。 PartCrafter的核心优势在于其创新性的模型架构设计。
首先它基于预训练的3D网格扩散变换器(DiT),继承了强大的编码器和解码器能力,这使得模型具备对整体三维形状的理解和生成能力。更关键的是,PartCrafter引入了组合潜在空间的概念,将3D物体不同语义部分通过一组独立而可分离的潜在标记(latent tokens)进行表示。这一设计使得模型可以同时处理多个部件的细节,忽略传统方法中对整合后的单一表示的依赖,显著增强了生成结构的灵活性与准确性。 此外,PartCrafter采用了层级注意力机制,这使得模型在生成过程中能够兼顾局部与全局信息。局部注意力帮助捕捉每个部件自身的细节和几何特征,而全局注意力则确保不同部件之间的协调和空间一致性,保证了整体3D结构的连贯性。这种结构化的信息流动不仅强化了语义部分之间的交互还提升了复杂多对象场景下模型的表现能力。
为了训练和验证这一模型,研究团队精心构建了包含丰富部件注释的新型数据集。这一数据集从大规模三维对象库中挖掘出细粒度的部件级标注,支持模型学习具备部件感知的生成策略。实验结果表明,PartCrafter在生成可分解的3D网格方面明显优于现有技术,特别是在重建输入图像中未能直接观察到的隐藏部件时,表现出强大的推断和生成能力。 相比于以往两步生成流程,PartCrafter统一了分割与重建,使得整个流程更简洁且易于优化。这种端到端的生成方式极大地拓展了3D生成技术在实际应用中的潜力。例如在工业设计、虚拟现实、游戏开发和自动驾驶等领域,精确且结构化的三维模型生成能够带来更逼真、更细致的视觉体验及更准确的场景理解。
PartCrafter的技术突破不仅体现在模型架构上,同时也突破了3D生成技术的研究瓶颈。通过利用扩散模型的强大生成能力,结合潜在表示的分离和层级注意力机制,PartCrafter成功实现了复杂结构的多部件3D生成。这种生成方式为三维场景理解和合成提供了新的思路,也为后续基于部分组合的3D设计系统奠定了坚实基础。 未来,随着更多数据以及更强计算资源的投入,PartCrafter及类似方法有望实现更高分辨率、更复杂的三维场景生成。结合多模态学习技术,还能进一步扩展对动态场景、多视角图像甚至视频输入的支持,推动三维生成技术迈向智能化和多元化发展。总之,PartCrafter作为结构化3D网格生成领域的重要里程碑,展示了组合潜在扩散技术在三维视觉建模中的巨大潜力和广阔前景,必将激发更多创新研究和应用实践的诞生。
。









