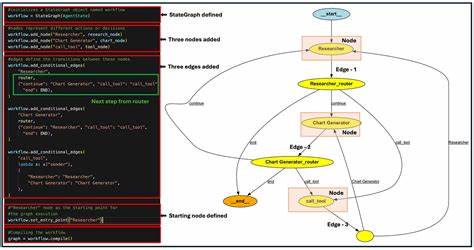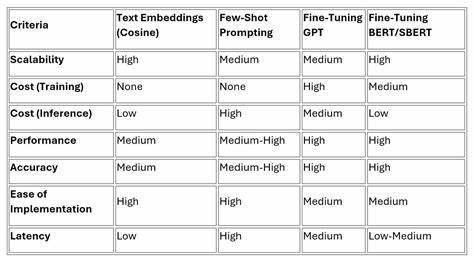
随着人工智能技术的不断发展,自然语言处理领域的模型也在持续进步。多分类文本分类作为自然语言处理中的经典任务,广泛应用于文本检索、信息过滤、情感分析等多个场景。近年来,基于预训练语言模型的微调技术逐渐成为提升文本分类效果的主流方案。本文聚焦于NeoBERT模型在多分类任务中的微调实践,结合实际项目经验,深入剖析微调过程中的关键步骤、面临的问题及解决思路。 选择适合的模型是文本分类微调的第一步。传统的BERT模型虽然性能突出,但存在上下文长度限制和训练过程相对较慢的缺点。
现代变种如DistilBERT在轻量化方面有优势,但在处理复杂文本时表现有限。NeoBERT作为新兴模型,凭借其架构上的创新和优化,备受关注。在实际测试过程中,NeoBERT在保持较好上下文理解能力的同时,兼顾了训练速度和资源消耗,适合处理较长文本和复杂分类任务。 然而,模型的选择仅仅是开始。训练环境的准备至关重要。由于深度学习模型训练对计算资源需求高,尤其是GPU的支持至关重要。
传统平台如Google Colab虽然提供免费GPU资源,但环境配置复杂且稳定性不足。亚马逊的Sagemaker Studio Lab因启动问题带来了困扰。最终,使用Lightning.ai平台成功搭建了稳定高效的训练环境,简化了依赖安装和GPU切换流程,保证训练过程的流畅与高效。 数据集的构建是文本分类成败的关键。该项目利用了由大型语言模型(LLM)辅助生成的数据集,涵盖800条示例,源自人工归纳和自动标注相结合的方法。数据包含了论文文本和对应的分类标签,文本信息通过PDF解析工具提取,为模型提供了真实且多样的语料资源。
在数据预处理阶段,针对部分标签进行了归类合并,减少类别数量,提升标签一致性,同时控制输入文本长度,避免因过长文本导致的训练效率低下。 在具体的训练流程中,首先使用了HuggingFace的AutoTokenizer对文本进行分词和编码,确保输入符合模型要求。通过Dataset工具将数据转换成训练和测试所需格式,实现了高效的数据传输和管理。模型加载时指定了分类标签数和标签映射关系,使得模型在训练和推理时能够准确理解目标类别。 训练参数的设置极大影响模型表现。本次微调过程中,采用了较小的学习率以保证稳定收敛,训练周期设定为20个epoch,并引入了自动批量大小调整机制,提升资源利用率。
为了缓解过拟合问题,应用了标签平滑技术和部分层冻结策略,冻结了除最后分类器外的大部分模型参数,仅解冻了部分层归一化层和倒数第二层Transformer模块。这种方式既保留了预训练知识,又为分类任务提供了足够的调优空间。 评价指标方面,采用加权F1分数作为模型性能度量,合理衡量了各类不平衡情况下的分类效果。训练过程中添加了日志记录与评估机制,确保能实时跟踪模型表现并保存最佳权重。在训练结束后,模型成功保存,方便后续部署和推理使用。 尽管采用了多项技术优化,模型仍面临一定过拟合问题,主要受限于数据集较小且标签噪声较大。
为解决这一难题,未来可以考虑多角度改进,如使用更高质量的文本抽取方式增加上下文信息,通过扩展数据集规模提升模型泛化能力,或者探索更先进的正则化方法和学习率调度策略。 此外,针对文本分类任务的复杂性,也可以尝试融合其他预训练模型,结合模型集成提升整体效果。利用迁移学习和半监督方法进一步挖掘无标注数据潜力,推动分类模型向更精准、更鲁棒方向发展。 总结来看,NeoBERT微调在多分类文本识别任务中展示了良好的应用前景。它兼顾了模型性能和训练效率,为处理长文本、多类别的问题提供了有效解决方案。然而,深度学习模型的成功离不开数据质量的保障和训练策略的合理设计。
未来持续优化训练流程和数据集建设,将为人工智能文本分类带来更多可能。对于人工智能工程师和研究者而言,不断探索创新的技术手段,结合丰富的场景需求,是推动行业前沿发展的关键。