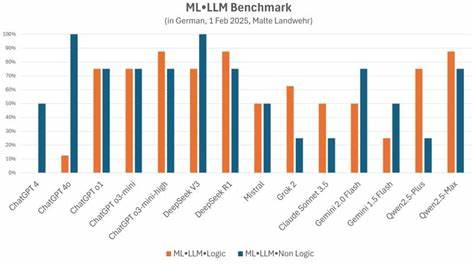
随着人工智能技术的迅猛发展,特别是大型语言模型(LLMs)的不断进步,其在自然语言处理领域的应用越来越广泛。然而,对于特定语言和文化背景的理解能力依然存在较大挑战。德语版本的知名电视问答节目《谁想成为百万富翁》(Wer wird Millionär?)作为一个充满文化特色和语言难度的知识竞赛,为评估本地大型语言模型提供了绝佳的测试平台。本文将深入探讨基于该节目问题的本地语言模型基准测试,揭示模型在德语理解及答题表现中的优劣和发展方向。 德语《谁想成为百万富翁》问答基准的设计极具特色,涵盖了45场游戏,每场包含15个由易到难递增的问题,涵盖文化、历史、地理、词汇游戏和惯用语等多方面内容。每次答题遇错即终止,游戏奖金作为答题水平的量化指标,真实反映了模型对德语复杂语境的理解和推理能力。
该测试不仅挑战了模型的知识储备,更考验了其对语言细节、双关和隐喻的把握能力。 对于本地大型语言模型,尤其运行于设备端(例如AMD Ryzen 5系列笔记本搭载16到32 GB内存的环境)的小型量化模型(如Q4_K_M),此基准考验了模型模型在资源有限环境下的表现优化。由于硬件限制,这些模型在保证实时响应的同时,必须对语义理解和推理能力做出平衡,避免因过度压缩影响答案的准确率。事实证明,很多本地部署的模型已能成功通过大部分基础题目,但在涉及德语特有的文化背景和语言习惯时依然存在明显短板。 对问题的深层次分析显示,前期题目经常涉及词语游戏和德语惯用表达,这些复杂的语言元素对模型提出了挑战。相比人类选手轻松理解的双关语或成语,模型的语义映射能力不足导致回答正确率偏低。
随着问题难度增加,模型所需调用的知识范围和推理逻辑日益厚重,稍有偏差即可能出现错误,提前结束游戏。其背后揭示了大型语言模型在语境理解与知识链接方面还有很大提升空间。 另一方面,云端部署的更大规模模型表现普遍优于本地小型量化模型,但也面临延迟和成本双重因素的制约。社区用户展示了多个云端模型参与基准测试的结果,获得了超过本地模型的平均奖金水平,这为模型规模与性能的平衡策略提供了参考。通过数据反馈,可以为模型训练引入更多德语语言学特性,增强对文化隐喻和复杂词汇的理解。 除了模型本身,测试项目的开源实现和社区参与也极大推动了该方向的发展。
测试仓库中包含详细的答题数据集和基准脚本,并提供了友好的本地运行环境配置指导。开发者可以轻松复现测试,调整模型参数,比较不同配置下的答题成绩,形成动态优化闭环。此外,排行榜功能直观展现了各模型的竞技表现,有助激励持续改进。 作为最接近真实使用场景的语言能力测验,德语《谁想成为百万富翁》基准不仅为语言模型提供了性能评估工具,更带来了对德语 NLP 领域深层问题的洞察。如何通过更精准的训练数据、更适配的模型结构和多模态输入融合,突破文化与语言障碍,是未来研究重点。结合语音、图像等多模态信息,实现更人性化的智能问答助理,也值得期待。
综上所述,当前本地大型语言模型在德语《谁想成为百万富翁》问答基准中表现出一定潜力,但在处理复杂德语习语和文化语境时仍显不足。通过持续的开源社区协作、硬件性能提升和算法创新,模型的语言理解和推理能力有望不断增强。该基准为语言模型开发者和研究者提供了宝贵的实测参考,是推动跨语言智能问答系统迈向更高水平的重要里程碑。未来,随着更多本地语种的引入和多语言融合的深入,语言模型将在全球化背景下发挥更大作用,助力智能化信息交互的广泛落地。 。