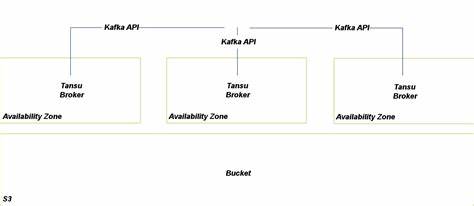
随着大数据和流式处理技术的不断发展,Apache Kafka成为了数据工程领域不可或缺的消息队列和流平台。然而,Kafka部署复杂、管理成本高以及对基础设施要求较高等问题,也促使行业内不断探索替代解决方案。其中,Tansu作为一个兼容Apache Kafka API的创新平台,正逐渐获得关注。Tansu不仅支持传统消息中间件的功能,还引入了以PostgreSQL和S3为核心的存储机制,极大地拓展了数据持久化和存储多样性的边界。对于寻求在成本、灵活性和数据持久化方面实现平衡的企业来说,Tansu成为了值得深入了解的选择。 首先,Tansu最大的亮点便是它完全兼容Apache Kafka的API,意味着现有Kafka应用和工具链可以无缝切换到Tansu,无需在客户端进行复杂的改造。
这种兼容性极大地降低了迁移门槛,同时保证了业务连续性。此外,Tansu提供了多种存储引擎选择,包括PostgreSQL、S3以及内存存储,灵活满足不同场景的需求,既支持企业级数据的长期存储,也适合仅需临时消息缓存的非生产环境。 存储机制的多样化是Tansu区别于传统Kafka的核心。PostgreSQL作为一个成熟的关系型数据库管理系统,其先进的事务处理能力和强大的数据一致性保障,使得消息数据在分布式环境下依然保持高度可靠。Tansu通过将消息持久化到PostgreSQL,并利用其持续归档和流式事务日志技术,确保数据完整性和高可用性。与此同时,借助S3的11个九设计目标,Tansu在数据的持久化存储方面达到了业界领先的安全级别。
S3的海量存储能力和高可用性让数据湖的建设更为简单快速,并支持将消息以Apache Parquet格式写入数据湖,方便进行后续的分析和计算。 在数据格式和模式管理上,Tansu支持多种主流的数据序列化格式,包括Apache Avro、JSON Schema和Protocol Buffers。这些模式可以被应用于不同主题(Topic)上,实现消息的严格格式校验,提升数据的准确性和一致性。配合Apache Iceberg和Delta Lake技术,Tansu可以将消息数据高效写入现代数据湖格式,从而兼容Spark、PyIceberg等生态工具,实现流数据和批处理的统一分析。 从操作角度来看,Tansu以单个静态链接二进制文件的形式发布,包含了核心组件如broker、proxy、topic、cat等,覆盖了消息生产、消费、主题管理以及代理等功能。broker为Kafka兼容的消息中间件核心,负责消息的接收和分发。
proxy则提供了透明的接口代理,使得不同应用可以方便连接和访问。cat命令行工具支持生产和消费不同格式的消息,极大简化了测试和调试过程。topic工具则覆盖了主题的创建和删除功能,方便用户在系统运行过程中灵活调整数据流架构。 安全性和监控方面,Tansu内置了Prometheus监听地址,方便收集和监控运营指标,有利于运维人员对系统性能和健康状况进行实时跟踪。结合PostgreSQL和S3的成熟技术栈,整体架构在保障数据安全和系统稳定性方面表现出色。此外,对于使用Docker和容器化环境的用户,Tansu也提供了完整的示例配置和环境文件,支持快速部署和扩展,满足现代云原生架构需求。
Tansu不仅具备强大的存储和兼容能力,其设计理念也体现了对可扩展性和开放性的高度关注。支持通过配置文件实现灵活的集群ID设置、监听地址定义以及指标暴露端口配置,为不同规模和复杂度的项目提供了极大便利。用户可以在本地利用SQLite或内存存储进行快速验证和测试,也可以在生产环境中无缝切换至PostgreSQL或S3,实现数据持久化和容灾备份。 在实际应用场景中,Tansu已成功应用于构建企业级消息队列,特别是在需要长期存储消息以便后续数据分析及溯源的场景中表现出色。开发者利用Tansu的Schema验证功能,保证了消息格式统一,避免了因格式混乱导致的处理失败。同时,通过Tansu写出的Parquet格式数据,分析师能够直接使用DuckDB或Apache Spark等分析工具进行复杂分析,无需额外的数据转换或导入,极大提升了数据使用效率。
对于那些关注数据湖建设和湖仓一体化的企业,Tansu提供了将流数据直接转换成适合大数据分析格式的可能。利用Iceberg Catalog和Delta Lake支持,Tansu消息流被保存为可查询的表格式数据,打通了流数据和批量数据的边界,有助于企业构建统一的数据资产平台。此外,支持本地文件系统和云存储的多种数据湖路径,使得Tansu不仅适用于公有云环境,也非常适合私有化部署。 搭建和维护Tansu环境的门槛较低,用户可以通过简单的Docker Compose文件快速启动完整集群,并根据需求切换存储引擎。配合详细的官方文档和示例数据,开发和运维团队能够迅速完成基础搭建和应用集成,且Tansu持续更新和完善,社区活跃,提供强有力的技术支持和生态保障。 总的来说,Tansu作为一个独具特色的Apache Kafka替代方案,引入了PostgreSQL和S3多存储引擎,兼顾了消息的高速流转和长时间持久存储的需求。
不仅支持丰富的数据格式和Schema验证,还结合了现代大数据架构中流批一体化的理念,大幅提升了系统的灵活性和扩展性。企业在选择消息中间件和数据流平台时,Tansu值得作为重要的参考选项,尤其在数据可靠性、存储成本和生态兼容性方面展现了明显优势。未来,随着数据湖和流处理技术的不断成熟,Tansu有望成为连接消息中间件和数据分析的桥梁,助力企业实现数据驱动的业务转型。