随着人工智能和机器学习技术的快速发展,越来越多的企业开始将模型部署应用于实际业务场景中,而如何保障这些模型在生产环境中的高效、稳定运行,成为发展过程中不可忽视的关键问题。这种背景下,MLOps作为机器学习领域的运维体系逐渐兴起,融合了软件工程、持续集成和模型生命周期管理等理念,帮助团队实现机器学习模型的自动化开发、测试、部署与监控。亚马逊云科技(AWS)旗下的SageMaker平台,提供了一整套支持机器学习端到端开发和部署的工具链,成为行业首选之一。本文将基于实际经验,剖析通过SageMaker实现MLOps建设的关键心得与有效方法。 在云端环境中开展MLOps,需要考虑如何构建标准化的开发环境、搭建自动化流水线、管理模型版本以及持续监控等多个环节。首先,成熟的MLOps流程应涵盖从实验协作的开发环境,到自动化训练和部署流水线,再到模型注册管理与性能评估,最后到监控与维护。
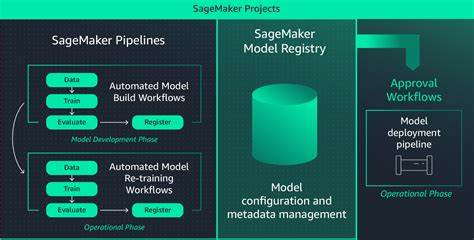
通过整合这些环节,团队能全面掌控模型生命周期,提升工作效率,减少人为差错,保障模型质量和业务价值。 SageMaker为机器学习工程师和数据科学家提供便捷的项目模板和环境支持。通过使用SageMaker Projects,团队能够快速启动新模型研发工作,自动集成代码管理和流水线触发机制,确保模型训练、评估和部署流程的规范。对于版本控制,建议采用基于Git的分支策略,将代码仓库主线区分为生产和开发分支,辅以特性分支进行新功能研制。这种管理方式能帮助团队实时追踪代码变化和模型发展历程。 值得注意的是,SageMaker引入了模型注册表功能,便于存储模型版本并追踪其来源、训练参数和性能指标等元数据。
在实际操作中,可以根据业务需求区分不同的模型组,例如开发环境模型组、生产环境中的冠军模型以及挑战者模型组等。这样的分类有利于实现蓝绿部署或金丝雀发布等渐进式上线策略,为生产环境带来更高的安全性和灵活性。 自动化流水线是实现MLOps的核心所在。借助SageMaker Pipelines及第三方CI/CD工具(如GitHub Actions或Jenkins),团队可以构建涵盖数据准备、模型训练、评估、注册及部署的闭环流水线。开发流程往往包括本地调试和云端触发,更新推送至分支后自动启动训练任务,训练完成后将模型注册入模型注册表,并由审批流程决定是否将产品投放生产环境。借助事件驱动机制和AWS Lambda函数的结合,可以实现部署和测试步骤自动化执行,降低人为干预带来的风险。
测试是保障模型质量和系统稳定性的关键环节。SageMaker提供了质量检查(QualityCheck)功能,可以自动检测模型性能和数据质量变化。同时,由于平台尚未提供完整的自动化集成和负载测试功能,团队通常需要定制Lambda触发的测试流程,将测试配置存储于DynamoDB中,当模型终端部署更新时自动执行测试并通过Slack等通讯工具反馈结果,这一方案兼具灵活性和自动化优势。 模型上线后的监控对保障持续性能至关重要。SageMaker Model Monitor支持数据质量、模型预测质量及数据漂移的周期性检测,虽受限于特定数据类型和监控频率,但在大部分结构化数据场景中表现良好。对于实时性能指标,如CPU、内存利用率,CloudWatch端点实例监控是有效工具。
企业在实际应用时,应结合自身业务需求和监控条件,设计合理的预警和响应机制。 实际项目中,根据模型应用场景的复杂度,大致可分为基础版和进阶版MLOps策略。基础版本更多应用于批处理和内部服务,流程较为简洁,强调快速迭代和稳定投入生产;而进阶方案引入多端点多模型共存机制,支持蓝绿发布、金丝雀测试及影子部署,实现生产环境的动态验证和风险控制。这两者策略虽然流程不同,但都依赖统一的版本管理、注册和自动化流水线框架,从而保证复用性和扩展性。 从架构实现层面看,借助Lambda函数结合CloudFormation或Terraform管理资源生命周期,实现自动化项目创建、分支管理、模型组建立等任务,极大提升运维效率。作者个人经验表明,使用Terraform管理Lambda函数配置,配合CloudFormation触发,有利于简化基础设施即代码的管理,并在多项目环境中实现统一标准. 近年来,AWS多个服务的弃用给MLOps构建带来挑战,比如CodeCommit、SageMaker Studio Classic和SageMaker Experiments的取消,促使团队重新评估技术栈和设计思路。
与此同时,文中提及的现代实践强调使用SageMaker提供的最新功能组合,以确保MLOps体系具备良好的可维护性和未来可拓展性。对于选用模型注册方案,是继续依赖SageMaker Model Registry还是采用MLflow搭建自定义追踪系统,则需结合团队的具体需求、监控能力与预期演化路径审慎抉择。 值得指出的是,尽管自动化模型重新训练在一些成熟模型运维体系中被视为必备特性,但作者基于实际工作经验指出该用例并非普适,因而文中并未将其列为标准流程组件。而在特征存储方面,虽然部分云厂商的MLOps框架(如GCP)推荐接入Feature Store系统,但根据作者观察,这一组件在目前实践中还远未成为大多数团队的标配。 整体来看,构建一套健壮且可扩展的MLOps体系需要兼顾业务需求和技术实现,尤其在云原生环境下,更需合理搭配版本控制、自动化流水线和监控机制。SageMaker结合AWS生态工具提供了极大便利,使得数据科学家和开发者能将精力更多聚焦于模型算法本身,而不是过多关注运维细节。
通过不断优化流水线节点、完善测试覆盖以及强化监控告警,组织能够有效提升模型在真实生产场景中的表现和稳定性。 未来,随着人工智能技术不断进步和业务应用场景多样化,MLOps平台也将持续演化。例如,更智能的自动化策略、更细粒度的模型性能评估以及更强大的实时监控功能,都将在进一步支撑企业加速AI转型中发挥关键作用。与此同时,团队建设和流程规范化依然是保障MLOps实施成效的基础,通过培养跨职能协作意识和标准化技术栈,组织才能实现长远持续的AI技术价值释放。 总的来说,在SageMaker平台实践MLOps,积累了宝贵的设计理念与技术方法。这包括严谨的代码管理策略、灵活配置的模型注册与版本追踪、自动化水平高效的训练与部署流水线及针对性强的测试监控方案。
希望这些经验能帮助更多技术团队稳步搭建起适合自身的机器学习运维体系,推动业务智能升级,迈向数字化未来。