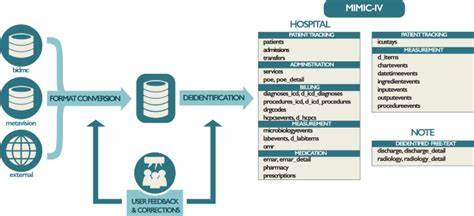
电子健康记录(EHR)数据在现代医疗研究和临床应用中扮演着极其重要的角色。随着机器学习和人工智能技术的不断进步,利用这些数据来提升疾病预测、诊断准确度及治疗效果成为当前热门课题。然而,现有的EHR数据往往分散且格式不一,缺乏统一的预处理标准,给研究者带来极大挑战。针对这一问题,MIMIC-IV数据集的开发与其专属数据处理管线的设计,为电子健康记录的深入研究提供了坚实基础。MIMIC(Medical Information Mart for Intensive Care)是由美国麻省理工学院开发的一套公开数据库,收集了大量重症监护病房患者的详细信息。最新版本MIMIC-IV较之前版本进行了数据结构的优化和范围的扩展,为医学界提供了更为丰富全面的数据资源。
虽然MIMIC资源公开且免费,但其原始数据格式复杂且多样,不同研究常因缺乏一致的数据处理流程导致结果难以比较与复现。由此诞生的MIMIC-IV数据处理管线,正是为解决这一瓶颈而设计。该管线由Mehak Gupta等学者提出,其目标在于为研究者提供一个灵活且全面的数据抽取、清洗和预处理工具,覆盖了MIMIC-IV深度医疗数据的多个方面。该处理方案不仅强调对数据的标准化操作,也兼顾应用的易用性,使得用户能够便捷地从原始数据到机器学习模型训练完成整个流程。MIMIC-IV数据处理管线采用模块化设计,涵盖了数据提取、缺失值和异常值处理、特征构建和变量转换等多个步骤。通过自动化脚本和配置文件,用户可以根据具体的研究需求自由定制参数。
最突出的是,该管线不仅局限于数据预处理,更集成了多种临床预测任务的支持,包括病人再入院率预测、住院时间预估、病死率分析和多种疾病表型预测。这些核心任务对应了临床实践中最实际和紧迫的需求,同时也是机器学习技术在医疗领域应用的重要方向。借助该管线,研究者可以快速搭建模型,进行跨任务的性能比较,极大提升了工作效率和研究成果的复现性。此外,管线源码公开托管在GitHub平台,保证了透明性和持续的社区维护。数据清洗是电子健康数据处理中不可忽视的环境。MIMIC-IV中包含患者人口统计、诊疗记录、生命体征和实验室检查结果等多种数据类型,这些数据往往存在不完整、格式混乱和异常点。
通过定制的去噪和校正方法,管线能够有效剔除无效信息,填补缺失数据,并规范时间序列的对齐,保证后续算法建模具有可靠的基础。临床预测任务是该管线设计的灵魂。再入院风险的精准预测能够辅助医院优化资源分配,减少医疗成本和患者负担。住院时间的预估帮助医生合理规划治疗方案和护理安排。病死率的分析为重症患者的风险评估提供科学依据。多样化的疾病表型预测则是实现个性化医疗的重要途径。
通过预构建的模型框架与评估指标,研究者能够迅速验证假设,开发创新的算法模型。该管线支持多种常见机器学习方法,包括传统的逻辑回归、随机森林以及前沿的深度学习模型。整合的数据流与接口设计降低了非专业人士的入门门槛,推动多学科合作,带动更多创新成果的诞生。MIMIC-IV数据处理管线的诞生及其开源发布,对于电子健康数据的标准化处理和临床机器学习研究具有重要意义。它不仅提升了科研的效率和质量,同时也促进了数据共享和结果的可比较性,助力国内外医疗研究机构建立更加完善的研究生态系统。未来,随着医学数据量激增和计算技术进步,类似的综合管线将成为智能医疗的基石。
综上所述,MIMIC-IV数据处理管线为医学数据分析和机器学习应用提供了一套高效且灵活的解决方案。通过规范化的数据预处理和支持多样化的临床任务,该工具显著推动了基于电子健康记录的研究发展。期待未来更多用户借助该管线实现创新突破,共同促进医疗健康事业的进步。 。