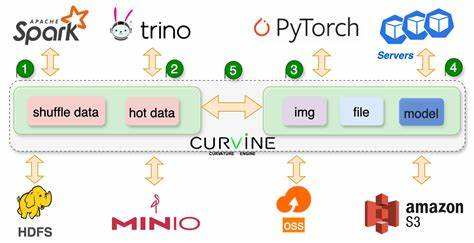
随着云计算与大数据技术的飞速发展,数据访问效率成为制约业务性能和用户体验提升的重要瓶颈。Curvine作为一款新兴的高性能分布式缓存系统,以开源姿态重磅登场,成为构建现代化数据平台的重要基石。其创新性的架构设计和智能缓存策略,使得数据存储与计算之间的桥梁更加稳定高效,让数据密集型应用享受前所未有的极速访问体验。 Curvine定位为云原生架构之上的分布式缓存解决方案,能够在存储与计算引擎之间插入智能缓存层,显著提升数据访问速度。相比传统云存储访问方式,Curvine在读延迟、带宽吞吐、IOPS以及并发连接数等多项性能指标上实现了数十到上百倍的提升。这种性能优势,使得Curvine不仅适用于大数据分析、人工智能训练等性能敏感型场景,也为企业节省了宝贵的资源开销。
系统选用Master集群作为元数据管理和缓存调度的核心,保证高速且稳定的请求处理能力。Worker节点则负责实际的数据缓存、IO处理及任务执行,通过分布式协同,提升整体集群的可扩展和稳定性。多语言客户端SDK支持Rust、Fuse、Java和Python等流行开发语言,降低开发者使用门槛,满足多样化业务需求。 Curvine支持两种灵活的挂载模式,分别是网状一致路径模式(CST Mode)和编排模式(Arch Mode)。CST模式适合结构清晰、生产环境要求路径映射简单直观的应用场景,是数据湖等多团队协作数据平台的理想选择。Arch模式则提供更强的路径抽象和转换能力,支持复杂存储层级与多云存储统一访问,助力企业构建灵活的数据接入体系。
在缓存策略方面,Curvine集合了被动响应和主动预测的多重智能机制。主动数据预加载功能支持业务高峰前预热缓存,确保访问性能稳定。其独特的智能缓存架构涵盖文件级与目录级的加载粒度,通过消除重复加载和分布式任务调度,实现带宽和存储资源的最大化节省。实时数据同步和一致性保障,为业务系统提供了多层次的缓存一致性选择,从无缓存一致性到强一致性,再到周期性检测,满足各种业务场景的需求。 尤其值得关注的是,Curvine通过FUSE接口实现了对POSIX语义的完美支持,使得缓存集群能够作为本地文件系统进行挂载,极大地提升了人工智能和机器学习训练的数据访问效率。DevOps和数据科学团队可以借助PyTorch、TensorFlow等主流框架,轻松读取Curvine缓存,享受近内存访问速度的优化,显著缩短模型训练时间和推理延迟。
与此同时,Curvine与主流大数据生态系统实现了无缝对接,涵盖Hadoop、Spark、Presto/Trino及Flink等框架。通过更换文件系统实现类及配置集群地址,用户无需修改业务代码,就能将存储路径无侵入地替换为Curvine缓存访问路径,最大化提升计算作业的执行效率。Curvine提供透明代理机制,助力已部署的Java应用自动享受缓存加速,无需停机改造,极大降低运维复杂度。 此外,Curvine的多集群管理能力让企业能够灵活维护生产、开发和机器学习专用集群,保证各类数据访问请求的隔离性及性能表现。Spark的自适应执行配置和Curvine插件扩展,进一步释放缓存加速潜力,实现复杂分析和实时计算的高效处理。Flink的表级集成让实时流式数据查询同样享受到低延迟优势,颠覆传统批处理和流计算之间的性能鸿沟。
安全性和数据完整性方面,Curvine同样足够用心。通过完善的缓存过期策略、数据副本冗余配置以及灵活的存储介质选择,确保缓存数据的高可用性和安全性。业务团队可以根据冷热数据访问特性,设定合理的缓存过期时间和存储层级,如内存缓存、SSD缓存以及传统磁盘缓存,以实现存储效率和访问速度的最佳平衡。 开源版本的公布,为开发者社区提供了全面的文档支持与快速入门指南。通过简单几步下载安装、编译和启动小型集群,用户即可快速体验Curvine非凡的性能表现。配套的基准测试方案和性能演示,直观展示Curvine在真实场景下的高吞吐和低延迟优势。
展望未来,Curvine致力于推动数据访问壁垒的进一步打破,将智能缓存技术普惠更多领域。无论是云原生微服务架构下的数据共享优化,还是边缘计算场景中的快速数据响应,Curvine均具备充分的扩展潜力。社区活跃度的持续提升以及丰富生态的持续完善,必将推动Curvine在全球范围内被更多企业和开发者认可应用。 总结来看,Curvine以高性能分布式缓存为核心,融合智能化缓存策略和广泛的生态集成,完美契合现代数据驱动业务的需求。它不仅能够显著降低云存储访问延迟和成本,还以开源的姿态促进技术创新和社区协作。借助Curvine,企业能够释放算力潜能,提升大数据和AI应用的响应速度与效率,赢得数字化转型的先机。
未来数据访问的新时代,正因Curvine的出现而变得触手可及。