在人工智能领域,尤其是自然语言处理(NLP)的快速发展中,大型语言模型(LLM)已成为推动技术进步的核心力量。然而,预训练这些模型通常需要数百万乃至数十亿美元的计算资源和海量数据,这对于大多数研究者和小型企业来说是难以负担的负担。本文将介绍一种创新且经济实惠的方案,如何在不到50美元的预算条件下,通过改良现有模型架构结合生物启发式神经网络,实现预训练一款性能媲美甚至超越Google BERT的语言模型。大规模的LLM训练往往依托庞大的硬件资源,如多卡GPU集群或TPU设备,以及庞大的数据集,这主要是由于传统的Transformer架构需要大量样本来捕获深层次语言规律。尽管Transformer模型本身在算力和建模能力上表现卓越,但其对训练数据的依赖依然很大,这也是造成高昂成本的根本原因之一。大量前沿研究开始关注神经网络的生物模拟,以期提升模型计算效率和泛化能力。
其中,脉冲神经网络(Spiking Neural Networks,SNN)和液态时间常数神经网络(Liquid Time Constant Networks,LTC)作为两种生物启发式机制,展现出独特的优势。SNN通过模仿生物神经元的脉冲通信机制,实现稀疏且能效极高的信息处理,神经元在达到阈值后"触发"信号,大幅减少无关计算;而LTC网络则通过动态调节神经元的时间常数,使得模型能够适应不同时间尺度的输入信号,更加精准地捕捉序列数据的时间动态。Harish SG作为一名安全研究员,基于自身对神经网络和Transformer架构的深入思考,将这两种生物启发机制引入经典的Llama语言模型中,开发了名为Arthemis的创新LLM版本。Arthemis模型通过替代Transformer中的关键部件,包括用脉冲神经网络取代多头注意力机制中的查询、键和值处理,并用液态时间常数神经网络替代传统的SwiGLU全连接前馈网络,成功提升了模型的时序推理和信息选择能力。具体来说,模型在注意力层面先将查询(Q)、键(K)、值(V)分别经过Leaky Integrate-and-Fire的脉冲神经元处理,这不仅可以保持记忆状态,还能够利用脉冲信号的稀疏性减少计算开销;之后结合旋转位置编码(RoPE)增强位置信息表达。前馈层则引入包含可适应时间常数的LTC模块,以实现多时间尺度的动态非线性转换,从而更好地拟合时间序列中的复杂关系。
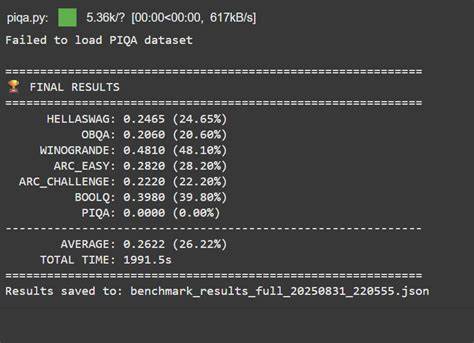
在硬件方面,Harish只利用了谷歌Colab Pro Plus计划中租用的单块NVIDIA A100 40GB显卡,训练时长约6小时20分钟,使用的显存也仅占用了24GB。这让整个预训练费用控制在了49美元之内,远低于传统大规模预训练的天价。训练数据方面,采用的是公开的babylm数据集中的1百万条样本(约1亿个token),虽然远不及Google BERT所使用的30亿级别tokens,但在有限数据下仍实现了相当优秀的语言理解和生成效果。初始模型(约1.5亿参数)即能生成语法正确、连贯的短句,展示了极佳的基础语言建模能力。随后,借助斯坦福大学的Alpaca指令数据进行微调,增强模型在指令理解和长文本生成上的表现。经过评测,Arthemis模型在多个自然语言理解基准测试中表现出色,尤其在Hella Swag和Arc-e任务中甚至超越了Google BERT。
值得一提的是,Google BERT的成功基于海量数据和昂贵算力投入,而Arthemis仅用极其有限的资源,就达成了这样的成果,无疑为低成本LLM开辟了新的可能。除了生成任务,Harish还基于基础模型训练了Arthemis嵌入模型,专注于句子和段落的语义表示。该模型能将文本映射到768维的密集向量空间,适用于语义搜索、文本分类、聚类等下游任务。在MTEB多任务评测中,Arthemis嵌入在分类、聚类、语义检索等多项指标上表现与Jina AI的较为成熟的Jina-embeddings-v2-base持平,显示出很强的泛化能力。这套低成本、高效能的LLM方案虽然暂时还不适合生产环境的高负载需求,但其在边缘计算和本地推理场景中有广泛应用潜力,例如智能语法纠错、自动完成建议等轻量级交互。通过对生物神经机制的借鉴和精巧的架构设计,Arthemis让越来越多的开发者和研究者能以有限的预算切入高质量语言模型的研究和应用。
该项目的代码和预训练模型也已发布于Huggingface平台,方便开发者下载安装、二次开发与实验,极大地降低了入门门槛。同时,Harish SG在社交媒体平台分享了更多技术细节和更新进展,为整个社区提供了丰富资源和支持。未来,随着Neuromorphic硬件和尖端算法的发展,类似脉冲神经网络和液态时间常数网络的生物启发方法必将成为LLM性能突破和资源优化的重要方向。Arthemis实验不仅验证了生物神经机制在现代神经网络中的价值,更鼓励更多创新布局,实现真正的低成本高效能人工智能。总之,这一研究表明,即使在资金和数据极其有限的条件下,结合生物神经科学及巧妙架构改进,依旧能够构建出具备竞争力的语言模型。这不仅丰富了自然语言处理的技术路径,也为普惠AI的推广奠定了坚实基础。
未来期待更多类似的开放式探索,推动技术边界,惠及更广泛的使用者和应用领域。 。