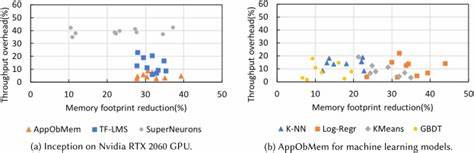
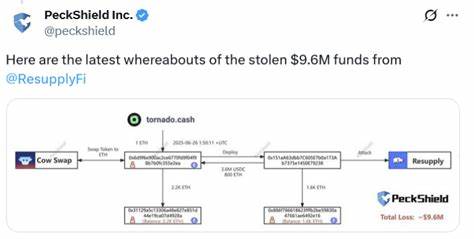
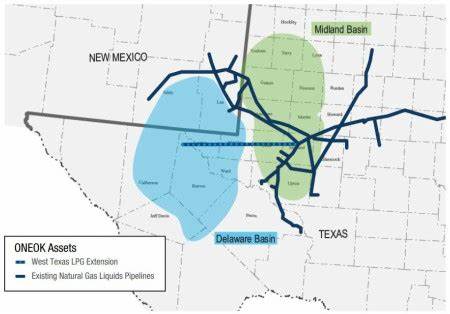
2025年6月,Meta公司在一桩备受关注的人工智能(AI)版权诉讼中取得了一个充满复杂性的部分胜利。这起案件由多位作家提起,指控Meta未经授权使用盗版图书库训练其大型语言模型(LLM),随后Meta以合理使用(Fair Use)为辩护依据。美国北加州地区法院的判决不仅是Meta的阶段性胜利,也为AI领域的版权法实践和未来的司法审判提供了关键的参考和启示。 在过去的几年中,版权持有者针对利用受版权保护作品训练人工智能模型的企业发起了多起诉讼,引发了版权法律和技术创新之间的激烈交锋。Meta被卷入了众多类似诉讼之一,其Llama语言模型的训练过程中确实使用了包含盗版图书的“影子图书馆”数据。Meta对其使用未经授权的图书进行了早期承认,但坚称这种使用属于合理使用范畴,并非直接侵权。
在诉讼关键阶段,双方于2025年3月提交了部分简易判决动议,目的在于请求法院对涉及版权侵权的某些主张做出裁定。Meta试图证明其行为符合合理使用标准,重点强调了其对原作的变革性使用以及未对市场造成显著损害。相对地,原告作者则争辩称,无论版权材料是否用于训练,只要获取方式违法,Meta都应承担直接侵犯版权责任。 法院法官Vince Chhabria的判决聚焦于合理使用的各项法律考量,尤其突出市场影响的关键作用。法院认定,Meta利用受版权保护的图书数据训练语言模型具有明确的变革性目的和性质,与原始作品的用途有本质区别。人工智能模型不是简单的复制,而是为生成多样化文本和执行复杂任务开发的创新性工具。
针对原告提出的市场损害理论,法院分别进行了严谨的评估。首先,作家们试图证明Llama模型能复述大量原著内容,便于用户免费获取,但专家证言表明模型在面临“对抗性提示”时,最多只能输出不超过50字的相关内容,这大大削弱了“免费替代”论点的合理性。其次,针对AI训练许可市场这种相对新兴且尚未成熟的经济领域,法院认为其所谓的许可费损失缺乏法律依据,无法被认定为合法市场损害。 法院还指出一个潜在但未被充分论证的“市场稀释”理论。该理论认为,AI训练可能以非侵权的形式大量产生与原著竞争的作品,从而间接削弱原作市场价值和作者利益。尽管法官判定这可能是未来版权争议中的关键争论点,然而由于原告未能提供实质证据支撑该论点,法院最终未予采纳。
判决中明确表明,若今后有确凿证据显示AI训练引发了市场稀释,相关案件可能会出现不一样的裁决结果。 这次判决对于AI开发商而言既是胜利也是警示。胜利在于法院否决了针对Meta复制盗版书籍用于训练且通过BitTorrent分发的直接侵权指控,确认了其训练行为在当前证据和法律框架下构成合理使用。然而,法院同时表达了对合理使用防御在未来类似案件中能否站住脚的保留态度,尤其强调了版权方可能通过追索“许可权”保护其经济利益。 法院对Meta关于若禁止未经许可使用将阻碍AI技术发展的论调亦做了严厉反驳,认为该观点“荒谬”,并警告相关企业应做好以合法授权内容训练模型的心理准备。法院指出,AI技术本身在市场中预期产出极高利润,若版权使用确实必要,企业必然会找到机制补偿版权方利益,技术发展和版权保护可以并行不悖。
整个判决结果在AI领域版权争议中具有破冰意义。部分合理使用的裁定对Meta公司而言是一场“苦乐参半”的胜利,既保留了利用海量版权内容训练AI的可能性,也提醒企业不能忽视版权市场潜在的法律风险。此案明确传递了版权方在AI版权案件中应着重挖掘“市场稀释”及间接竞争损害的策略,这可能成为未来诉讼的关键切入点。 此外,法院澄清,这次判决并不代表Meta利用版权所有作品训练AI的行为完全合法,而是本案原告作家未能针对关键法律点展开有效举证。未来其他案件若能充分论证AI训练造成版权持有人实质损害,则公平使用防线可能不被支持。这成为科技企业及版权持有者双方不得不认真考虑的法律警示。
这场围绕AI版权边界的诉讼,不仅引发了社会各界对数字时代知识产权保护的广泛关注,也对AI模型训练方法的合法合规性提出了现实挑战。随著技术进步不断拓展AI能力,现有的版权法律体系正面临调整和完善的紧迫需求。未来,可能需要立法层面以及司法实践中进一步明确何种AI训练行为构成合理使用与侵权,怎样建立版权许可与补偿机制,保障创新与创作双赢。 简而言之,这起案件和判决为全球AI版权纠纷树立了重要的法律标杆,让各方认识到市场影响评估在AI版权保护中的中枢作用。Meta的胜利并非彻底泯灭版权持有者的权益诉求,而是促使双方在未来围绕AI训练授权、版权赔偿及合理使用标准展开更为深入且严谨的对话与博弈。技术的飞速发展需要伴随着法律框架的动态完善,只有平衡维护创新与尊重版权,才能实现人工智能生态的健康可持续发展。
。